内容
人文学研究でコーパスを用いる意義
コーパス(大規模言語データベース)を人文学研究に活用することには、いくつか重要な意義があります。
再現性の向上
従来の人文学では、研究者ごとの解釈や直感に頼る部分が大きく、同じ資料から異なる解釈が生まれることもしばしばでした。コーパスを用いることで、誰もが同じデータにアクセスし、同じ検索手順を踏めば同様の結果を得られるため、研究結果の検証や追試が容易になります。
確証バイアスの回避
確証バイアスとは、自分の仮説に都合の良い事例ばかりを集めてしまう傾向のことです。コーパス上で網羅的にデータを観察すれば、恣意的に例を選ぶ余地が減り、仮説に合致する例だけでなく反証例も含めて客観的に検討できます。
解釈の根拠の可視化
コーパスから得られた結果(例えばある語の使用頻度や用例の一覧)は、解釈を裏付ける明確なエビデンスとなります。具体的なデータを示せるため、従来の曖昧な主観的判断に比べて説得力が増します。
このようにコーパスは、人文学を単に「データ化」する以上の意味を持っています。それは人文学を「解釈の学」から「実証の学」へと開き、データによる客観的観察と人間的な解釈とを統合する試みでもあります。
コーパスの定義と基本的特徴
コーパス(Corpus)とは、現実に使用された大量の言語データを電子的に集積・構造化したデータベースのことです。テキストデータ(文章や会話の書き起こし)がコンピュータで検索・分析できる形で蓄えられており、日本語では「言語コーパス」などと呼ぶこともあります。典型的には数百万語から数億語規模にも及ぶ自然言語の用例を含み、言語学の研究、辞書や文法書の編纂、言語教育などで重要なリソースとして活用されています。
コーパスの種類
コーパスには様々な種類があり、構築方法や用途によって分類できます。
均衡コーパス(Balanced Corpus)
あらかじめコーパスの規模や収集範囲を定め、言語全体を代表するように多様なジャンルからバランスよくデータを集めて構築されたコーパス。言語のスナップショットであり、特定の時期・領域の言語使用を偏りなく反映することを目指します。典型例として英国英語の BNC(約1億語)や、日本語の BCCWJ(約1億語)があります。
モニターコーパス(Monitor Corpus)
継続的にデータが追加・更新されていく動的なコーパス。言語の変化を逐次「監視(モニター)」する目的で設計されており、新語の出現状況や語の使用頻度の変遷を追跡するのに向いています。例えばアメリカ英語の大型コーパスである COCA などがモニターコーパスに該当します。
アノテーション付きコーパス
原文テキストに品詞や構文構造、意味情報などの注釈(アノテーション)が付与されたコーパス。「名詞句に限定して検索する」「主語と目的語の関係を持つ文を抽出する」など高度な分析が可能です。代表例として英語の Penn Treebank や、日本語では BCCWJ(形態素・品詞情報付きで提供)などが挙げられます。
パラレルコーパス(Parallel Corpus)
二つ以上の言語で内容が対応しているテキストを対にして収録したコーパス。翻訳テキストの原文と訳文を揃えたもので、多言語の翻訳研究や機械翻訳の開発にしばしば用いられます。例えば Europarl コーパスは典型的なパラレルコーパスです。
専門分野コーパス(ドメインコーパス)
特定の専門領域・ジャンルに特化してテキストを集めたコーパス。例えば医学論文だけを集めた医学英語コーパス、法律文書のコーパス、ある作家の全作品コーパスなど。人文学の研究者が自前でコーパスを構築する場合も、自分の研究対象に合わせたドメインコーパスを作るケースが多いでしょう。
学習者コーパス(Learner Corpus)
第二言語・外国語としてその言語を学ぶ学習者が実際に書いた作文や発話を収集したコーパス。非母語話者特有の誤用や中間言語の特徴をデータとして記録している点に特徴があり、応用言語学や言語教育の研究で重宝されます。
ウェブコーパス
インターネット上の大量のウェブページからテキストを収集して構築されたコーパス。圧倒的なデータ量と多様性を確保できるのが利点で、珍しい表現例や最新の流行語・専門語も見つけやすい魅力があります。一方で代表性の担保が難しい、品質管理の問題、著作権やプライバシーへの配慮も必要です。
大切なのは、自身の研究目的に合ったコーパスを選ぶことです。言語の現在の全体像を知りたいなら均衡コーパス、新語の出現を追跡したいならモニターコーパス、特定分野の表現を調べたいなら専門分野コーパス、といった具合に使い分けると良いでしょう。
研究目的に応じたコーパス選択のポイント
実際にコーパスを選んだり自作したりする際には、いくつか考慮すべきポイントがあります。
- ●代表性:コーパスが自分の研究したい言語現象にとって充分に代表的かを考えましょう。コーパスの構成要素(ジャンルや話者属性など)が自分の研究の対象を偏りなくカバーしているかを確認することが重要です。
- ●ジャンル・文体のバランス:特に均衡コーパス以外では、何らかの偏りがあるものです。例えば Web 由来のコーパスはブログや会話調の文章が多めになる傾向があります。自分の分析したいジャンルが十分な量含まれているかを検討しましょう。
- ●データの品質とノイズ:コーパスのテキストデータがどの程度クリーンかも重要です。ノイズの多いコーパスを使うと分析結果にも影響が出るため、可能ならテキストクリーニングがなされているか、注釈精度が高いか、といった点も確認すると良いでしょう。
- ●著作権・プライバシー:特に自分で新たにコーパスを構築する場合は、収集するテキストの権利処理に気を配る必要があります。著作権で保護された文章を無断で大量に収集・公開することは法律上問題がありますし、日記やSNS投稿などには個人情報が含まれる可能性もあります。既存の公開コーパスを利用する場合でも、その利用許諾範囲(商用利用の可否や再配布の禁止等)を守ることが大切です。
コーパス研究のアプローチ:Corpus-based と Corpus-driven
コーパスを用いた研究スタイルには、大きく分けて二つのアプローチが存在します。
コーパス検証型(Corpus-based)
あらかじめ設定した理論や仮説をコーパスデータによって検証する手法です。研究者は分析前に「○○という表現は話し言葉で多用されるはずだ」「英語の受動態は書き言葉で頻出するだろう」といった仮説や問いを立て、それに基づきコーパス検索と結果分析を行います。
メリット:明確な問いに答える形で分析を進めるため結果の解釈がしやすく、エビデンスが直接仮説の支持・反証に結びつく。
デメリット:仮説にない現象は見落としがちになる。
コーパス駆動型(Corpus-driven)
明確な仮説を最初から持たず、コーパスデータそのものの中からパターンや法則を見出そうとする手法です。既存の理論にとらわれず大量のデータを観察し、そこから知見を導く「データ主導(ボトムアップ)」のアプローチになります。
メリット:予期しないパターンの発見につながりやすく、新しい言語事実や規則性を発掘できる。
デメリット:分析範囲が広大になり焦点が絞りにくい。膨大なパターンの中から意味のあるものを取捨選択して理論化するには熟練を要する。
アプローチの比較と統合
以上の二つのアプローチにはそれぞれ利点と欠点があり、相補的な関係にあります。コーパス検証型は演繹的(トップダウン)であり理論の検証に向いている一方、コーパス駆動型は帰納的(ボトムアップ)で新知見の発見に優れています。実際の研究では、両者を組み合わせることで互いの欠点を補うことが多いです。例えば、初めにコーパス駆動的にデータを探索して興味深いパターンを発見し、その後コーパス検証型の手法で追加データを用いて仮説を検証する、といった手順です。初心者のうちは、まずは検証型のように明確な問いを立ててコーパス分析を始めてみるのが取り組みやすいでしょう。
コーパス検索実習:Sketch Engine を利用した分析
以上でコーパスの基礎知識と理論的背景を概観しました。ここからは実際にコーパスを検索・分析する手順を学びましょう。実習には、世界的に広く使われているコーパス検索ツールである Sketch Engine を中心に扱います。日本語コーパス向けのツールである国立国語研究所の「中納言」にも触れます。
Sketch Engine とは何か
Sketch Engine(スケッチエンジン)は、チェコの Lexical Computing 社が開発した強力なオンラインコーパス検索・分析ツールです。世界各国の言語コーパス(100以上の言語、500以上のコーパス)を収録しており、研究用途から商用まで幅広く利用されています。例えば英語の BNC や米語の COCA、日本語のコーパスとしてはウェブから収集した日本語ウェブコーパスなども含まれています。特徴的な機能として、Word Sketch と呼ばれるコロケーションの自動要約機能があり、ある単語の用法を「主語になる名詞一覧」「目的語になる名詞一覧」「修飾する形容詞一覧」など文法関係ごとにまとめて表示できます。
中納言(NINJAL 中納言)の紹介
日本語のコーパスを使いたい場合には、国立国語研究所が提供する「中納言」というウェブアプリケーションも有力な選択肢です。中納言は主に同研究所が構築した日本語コーパス(現代日本語書き言葉均衡コーパス=BCCWJ や日本語話し言葉コーパス=CSJ、日本語歴史コーパス=CHJ など)を検索するためのツールです。形態素解析済みのデータに対して、高度な検索(品詞や活用形を指定した検索など)が可能で、日本語研究者にとって貴重な環境です。
基本的な検索方法(フリーワード検索と CQL)
Sketch Engine では、大きく分けて二通りの検索方法があります。一つはキーワードをそのまま入力して検索する簡易な方法(フリーワード検索)、もう一つは CQL(Corpus Query Language)と呼ばれるクエリ言語を用いて高度な条件を指定する方法です。
フリーワード検索では、調べたい単語やフレーズを入力し Enter キーを押すだけで検索が実行されます。基本的には部分一致検索(understood なども含む)になります。
CQL では検索したい語や品詞を [ ] で囲んで指定します。例えば [lemma="understand"] と入力すると、見出し語が understand である単語、すなわち understand の任意の活用形(understands, understood, understanding など)をまとめて検索できます。また [word="understand"] [tag="NN.*"] のようにスペースで区切って連続した条件を書くと、「understand という単語に続いて名詞(NN)が現れるパターン」を検索します。CQL では正規表現や論理演算子も使えるため、「5文字以上の名詞」や「同一文中で近距離に出現する2語」なども複雑な検索も表現できます。
基本機能:KWIC 表示・頻度分析・共起分析
KWIC 表示(コンコーダンス)
検索を実行すると、デフォルトでは結果は KWIC 形式で表示されます。KWIC とは "Key Word in Context" の略で、検索語を中心に前後の文脈(コンテクスト)を数語ずつ表示したものです。これによって、検索語がどのような文脈で使われているかを直感的に把握できます。KWIC 表示をスクロールして眺めるだけでも、その語の典型的な使われ方(例えば頻出するフレーズや文型)を掴むことができます。
頻度分析
検索語の出現頻度は結果画面上部に表示されます。SketchEngine ではヒット件数とともに、コーパス全体における百万語あたり頻度(per million words; pmw)も表示されることがあります。頻度情報は、語がどれほど一般的かを示す指標であり、異なる語を比較したりジャンル間で出現率を比べたりする際に有用です。また Frequency List(頻度表)機能もあり、コーパス中で最も頻出する単語を列挙したり、特定の条件下での頻度順位を調べたりできます。
共起(コロケーション)分析
コーパス研究では、ある語と一緒によく現れる語(共起語, collocate)を調べることも重要です。Sketch Engine で検索した結果画面には「Collocations(コロケーション)」タブや「Word Sketch」タブがあります。Collocations 機能では、検索語の左右一定範囲内に出現する単語で統計的に有意に頻度の高いものがリストアップされます。さらに「Word Sketch」機能を使うと、検索語を中心とした文法関係ごとの共起一覧が得られます。例えば「オブジェクト(目的語)として現れる名詞」として what, it, this, things など、「副詞的に修飾する語」として fully, really, how などが抽出され、それぞれの共起頻度やスコアが表示されます。
検索例:BNC における understand の使用傾向
ここでは実際の研究のミニチュア版として、BNC(英国英語コーパス)における understand の使用傾向を分析してみます。Sketch Engine でコーパスとして BNC を選択し、検索バーに [lemma="understand"] と入力して検索します。結果として、BNC 全体での understand のヒット件数と KWIC 一覧が得られ、BNC 約1億語中のヒット件数はおよそ数千件程度になります。
KWIC 一覧をざっと眺めると、understand が使われる文脈にはいくつかパターンがあることが分かります。まず目立つのは、一人称主語との組み合わせです。「I understand」で始まる文が頻出しており、「I understand your point」のように相手の発言や事情を受けて理解を示す用法が多く見られます。さらに共起分析からは、understand と頻繁に共起する副詞に fully があります。「fully understand」は「完全に理解する」という意味で用いられ、「I don't fully understand」や「You must fully understand」のように深い理解の有無を強調しています。
このように、コーパスを使えばある語の使われ方や意味の広がりをデータに基づいて明らかにすることができます。頻度情報はその語の一般性や重要度を示し、共起は語のネットワークや特徴的なフレーズを教えてくれます。KWIC による文脈の観察からは、語の持つニュアンスの違いや使用場面の典型例を掴むことができます。これらはすべて、従来の辞書や直感だけに頼っていたのでは得にくかった知見です。
ケーススタディ:Behavioral Profile 分析とは
前節までで、コーパスから単語を検索し、KWIC や頻度・共起を観察する基本的な手順を学びました。ここからは一歩進んで、コーパスから得られた用例を 多次元的に注釈し、語の意味のあり方そのものをデータから抽出する本格的な分析手法を紹介します。それが Behavioral Profile(行動プロファイル、以下 BP)分析です。BP 分析は Stefan Th. Gries(2010)が体系化し、Divjak(2010)、Glynn(2014)らによって発展してきた、認知言語学・コーパス言語学における代表的な定量分析手法のひとつです。
BP 分析の発想:意味は「振る舞いの束」である
伝統的な辞書編集や意味記述では、語義は研究者の内省や少数の例文に基づいて整理されてきました。たとえば understand の語義は辞書ごとに「理解する/察する/聞き知る/同情する」などと分類されますが、その区切り方は研究者・辞書ごとに異なり、語義の数や境界は一意に定まりません。
BP 分析はこの状況に対し、「ある語の意味は、その語が現れる文脈の統語的・意味的・談話的な振る舞い(behavior)の総体として観察可能である」という立場を取ります。すなわち、各用例について「どのような主語と現れるか/どのような目的語を取るか/どの時制で使われるか/どのような副詞と共起するか/どの談話的位置にあるか」といった素性を多次元的に記述し、その素性ベクトルを多変量解析(多重対応分析 MCA や階層クラスター分析 HCA)にかけることで、語義のクラスターをデータからボトムアップに抽出するのです。
この発想は、Wittgenstein 的な「意味は使用にある」という見方をコーパスで定量化するものと言えます。研究者が「この語にはこれだけの語義がある」と先に決めるのではなく、データの中で似た振る舞いをする用例同士が自然にクラスターを形成し、それが「語義」として浮かび上がってくる──これが BP 分析の核となるアイデアです。
分析パイプライン(understand の場合)
具体的に understand を題材にした BP 分析の流れを示します。これは現在進行中の研究プロジェクト understand/analysis での実際の手順です。
- コーパスからの全件抽出:BNC(British National Corpus、約1億語)から Sketch Engine の API 経由で動詞 understand の用例を全件取得する。CQL では
[lemma="understand"]と指定するだけで、understand / understands / understood / understanding といったすべての活用形が一括で抽出できる。BNC では数万件規模になる。 - 前後文脈の収集:各用例について、当該文(target sentence)と前後 1 文ずつ(合計 3 文)の文脈を収集する。Layer 5 の談話的素性(応答か開始か、誰に対する発話か等)を判定するためには、対象文だけでは情報が不足するためである。
- メタデータの取得:BNC の文書メタデータからモード(書き言葉/話し言葉)、ジャンル、サブジャンルを取得する。これは BP 分析の素性として組み込まれる。
- 多次元アノテーション:各用例に対して 27 個の素性を分類カテゴリで付与する(次節 6.8 で詳述)。これが BP 分析の中核作業である。
- 統計解析:用例 × 素性の行列に対して多変量解析をかけ、用例を低次元空間に布置したり、似た振る舞いの用例同士を束ねたりする(具体的な手法の選択肢は次の囲みで詳述)。
- クラスター解釈:得られた各クラスターについて、どの素性がどのように偏って分布しているかを観察し、語義タイプとして解釈する。さらに FrameNet、OED、LDOCE など既存の語義分類と対照し、データから浮かび上がった語義構造が伝統的記述とどう一致/乖離するかを検討する。
統計解析の選択肢:手法は一つではない
「BP 分析」と一口に言っても、用例 × 素性の行列をどう料理するかは研究者によって異なります。問いの性質や素性の型(カテゴリ/二値/頻度プロファイル)に応じて、次のような多変量手法が単独でも組み合わせでも使われてきました。
- ・階層クラスター分析(HCA, hierarchical cluster analysis):Gries (2010) や Divjak & Gries (2006) の原型的な BP 研究で使われる定番。用例ごとの素性比率プロファイル間距離(多くは Canberra / cosine 距離)を計算し、Ward 法等で樹形図を描く。「どの用例同士が似ているか」を直感的に可視化できる。
- ・対応分析(CA, correspondence analysis):2 つのカテゴリ変数のクロス集計表に対して、行と同時に列も低次元空間に布置する古典的手法(Benzécri)。素性とその値の関係を観察するのに適しており、人文系コーパス研究で広く用いられる。
- ・多重対応分析(MCA, multiple correspondence analysis):CA を多変量に拡張したもの。多数のカテゴリ素性を同時に扱える点が BP 分析と相性がよく、Glynn (2010, 2014) を中心に近年の主流手法のひとつ。本プロジェクト(understand)でもこれを採用予定。
- ・多次元尺度構成法(MDS, multidimensional scaling):用例間の距離行列から、距離関係を保つ低次元配置を推定する。Divjak (2010) のロシア語類義動詞の BP 研究で用いられた。非計量 MDS は順序的な距離関係のみを保つ。
- ・主成分分析(PCA):素性を数値化(ダミー変数化)した場合に使える線形次元削減。連続量を中心とする際に。
- ・布置型クラスタリング(k-means、PAM 等):HCA とは別系統のクラスター手法。クラスター数 k を事前に決める/決めない選択がある。
- ・混合モデル・潜在クラス分析(LCA):用例が「いくつかの隠れた語義クラスから確率的に生成された」と仮定して推定する。離散的な語義カテゴリの存在を統計的にテストできる。
- ・配置頻度分析(CFA, configural frequency analysis):素性値の組み合わせ(configuration)ごとに出現頻度が偶然より多いか/少ないかを検定する。「この組み合わせは有意に多い/少ない」というかたちで型を抽出できる。
- ・予測モデル(多項ロジスティック回帰・ランダムフォレスト・条件付き推論木など):素性から語義/構文選択/メタデータを予測させ、変数重要度から「どの素性が語義の弁別に効いているか」を読む使い方。Gries 自身の近年の研究でも採用される。
- ・ネットワーク分析・埋め込み手法:用例を文埋め込みベクトルに変換して可視化する DCA 系列の手法(後述 6.11 で紹介)も、広い意味では BP 分析の延長線上に置ける。
どの手法を選ぶかは、(a) 探索的か仮説検証か、(b) 結果を可視化したいかカテゴリ予測精度を測りたいか、(c) 素性が完全にカテゴリ型か数値混在か、といった研究設計次第です。本プロジェクトでは、(a) 探索的なクラスター発見 + (b) 二次元可視化を重視するため、MCA で次元削減 → HCA でクラスター抽出 → 各クラスターの素性分布を観察という王道の組み合わせを採用しますが、結果の頑健性を確認するために MDS や k-means など別手法での再実行も計画しています。
今後の研究可能性:最新のデータサイエンス/AI 技術と BP 分析
これまで紹介した手法はいずれも 2000〜2010 年代までに整備された伝統的な多変量解析です。Behavioral Profile 分析は本来「用例の振る舞いをデータとして観察する」という発想なので、最新のデータサイエンス・AI 技術を取り入れて拡張する余地が大きく残されています。まだ本格的な研究としては十分に切り拓かれていない領域ですが、たとえば次のような方向性が考えられます。
- ・ハイブリッド素性表現(記号 × 埋め込み):研究者が定義した 27 個のカテゴリ素性に加えて、各用例の文埋め込みベクトル(BERT / E5 / SBERT 等)を連続素性として組み合わせる。記号的な解釈可能性と分布的な細やかさを両立できる。
- ・ノンパラメトリック・ベイズ的クラスタリング:クラスター数 k を事前に決めず、ディリクレ過程混合モデル(DPMM)や階層ディリクレ過程(HDP)でデータから語義数そのものを推定する。「understand には何種類の語義があるのか」という問いに統計的に答えられる。
- ・グラフベース手法とコミュニティ検出:用例をノード、用例間類似度をエッジとするネットワークを構築し、Louvain / Leiden などのコミュニティ検出で語義クラスターを抽出する。HCA より柔軟で、用例間の「橋渡し」関係を可視化しやすい。
- ・推論モデル(reasoning LLM)による Layer 5 注釈:談話・語用論的判断はもっとも難しいレイヤーだが、o3 / o4-mini / Claude Sonnet 4.6 などの推論モデルは「なぜこの値か」を chain-of-thought で展開できるため、人手注釈との一致率を底上げできる可能性がある。
- ・アクティブラーニング × Human-in-the-loop:LLM が自信のない用例(モデル間不一致が大きい、確率が低い等)を自動で抽出し、人間アノテーターには「迷う事例」だけを集中投入する。人手コストを抑えつつ精度を最大化する設計。
- ・説明可能 AI(XAI)の応用:用例 → 語義クラスターを予測する分類器を学習させ、SHAP 値や LIMEを使って「どの素性がどのクラスター判定にどれだけ寄与したか」を定量化する。クラスター解釈の客観化が進む。
- ・反事実介入(counterfactual analysis):「もしこの用例の主語が impersonal_it でなく 1sg だったら、クラスター帰属はどう変わるか?」を AI で生成・予測し、素性の因果的役割を探る。Pearl 流の因果推論を語義研究に持ち込む発想。
- ・多タスク学習による横断研究:understand / explain / clarify / justify / comprehend など説明・理解関連動詞群を共通の素性スキーマで同時にモデリングし、語彙場(lexical field)全体の構造を一つの空間で可視化する。BP 分析を「動詞 1 つの語義図」から「動詞群の意味地図」へ拡張。
- ・マルチモーダル BP(spoken BNC への応用):話し言葉用例には、文字列情報に加えて韻律(F0・強度・話速)や Whisper / wav2vec 音声埋め込みを素性として組み込むことができる。"I understand" が同調なのか諦めなのか皮肉なのかを音響特徴から区別できる可能性がある。
- ・通時的・言語横断的 BP:歴史コーパス(CHJ、EEBO、Hansard 等)に同じスキーマを適用して語義の数世紀にわたる漂流を追跡する、あるいは understand / verstehen / 理解する / comprendre / 了解 を同じ素性で並べて言語横断の意味マップを作る。LLM 注釈のスケーラビリティが、これまで現実的でなかったこの種の比較研究を可能にしつつある。
- ・生成 AI による「空白領域」の探索:MCA で布置された用例空間に「データが薄い領域」が見つかったとき、LLM に「この素性プロファイルを満たす用例文を生成して」と指示し、合成用例で空白を埋めて理論的可能性を探る。実コーパスの欠落を補完的に分析できる。
- ・ベクトルデータベース + RAG 型用例検索:注釈済み用例をベクトル DB(Pinecone / Weaviate / Chroma 等)にインデックスし、研究者が新しい用例を与えると「最も近い既存用例 k 件とその素性ラベル」を即座に返すインタラクティブなツールを構築できる。授業・辞書編集・翻訳支援にも応用可能。
これらはいずれも「BP 分析 + 何か新しい技術」という形で、人文学的な解釈枠組みを守りながら分析の解像度と射程を拡張する方向性です。重要なのは、技術はあくまで道具であり、ボトムアップに語の振る舞いを観察するという BP 分析の哲学そのものは変わらないという点です。むしろ、最新の AI 技術によって「これまで規模・コスト・難易度の壁で諦められていた問い」に手が届くようになることで、人文学的研究の問いの立て方そのものが拡張されていくのではないかと期待されます。
このパイプラインの要点は、「研究者の直感で語義を切り分ける」のではなく「データの中で似た振る舞いをする用例を統計的に束ね、結果として現れたクラスターを解釈する」という方向性にあります。これは前節(6.5)で扱った Corpus-driven アプローチを多変量解析と結びつけた、もっとも徹底したボトムアップ型コーパス研究の一例だと言えます。
27 項目の素性スキーマ:何を、どう記述するか
BP 分析の心臓部は、用例を記述する素性スキーマ(feature schema)の設計です。understand プロジェクトでは、各用例に 27 個の素性を付与します。すべての素性は閉じた選択肢を持つカテゴリ変数で、自由記述は許されません(後続の MCA / HCA に直接投入できるようにするため)。また、素性が当てはまらない場合は一律に NA(適用不能)が割り当てられます。
27 個の素性は、判定の難易度と理論的位置づけによって 5 つのレイヤーに整理されています。レイヤー 1 から 5 へと進むにつれて、判定が形式的(統語的)なものから解釈的(語用論的)なものへと移っていきます。なお、これらの 27 項目とは別に、BNC の文書メタデータから取得するモード/ジャンル/サブジャンルの 3 項目(F28–F30)が分析に加わりますが、これらは LLM の判定対象ではなくコーパス側から直接読み込まれます。
Layer 1:形態統語的形式(12 項目、F01–F12)
統語構造から機械的に決まる項目群。LLM でも安定して付与可能で、いわば「土台」となる素性。
F01 inflection(屈折形):understand 動詞の品詞タグ (CLAWS C5)。文中での形態を判定する。CLAWS タグは KWIC ヘッダーに表示されています。
💡 選択肢の意味と例(クリックで開閉)
VVB | 原形 (定形)。一人称単複・二人称・三人称複数の現在形、命令、仮定、補文位置。例: "I understand" / "we understand" / "Understand my point." |
VV0 | 原形 (旧タグ)。VVB と実質同等で、本データでは稀。VVB を選んで問題ないケースが多い。 |
VVD | 過去形 (定形)。例: "I understood the answer" / "She finally understood". 過去分詞 (have/be + understood) は VVN なので注意。 |
VVN | 過去分詞。完了形 ("have understood", "had understood") と受動態 ("is understood", "was understood", "to be understood") の両方を含む。 |
VVG | -ing 形。動名詞 ("Understanding the problem is the first step")、進行形 (まれ: "I'm understanding more and more")、分詞節 ("Understanding her position, I agreed") を含む。※ 名詞用法 "an understanding" は本データから除外済み。 |
VVZ | 三人称単数現在。例: "She understands" / "He understands" / "The committee understands". |
VVI | 不定詞。to 不定詞 ("to understand", "in order to understand") とモーダル後の bare infinitive ("can understand", "must understand", "should understand", "will understand") の両方を含む。 |
F02 subj_person(主語の人称・数):understand の文法的主語の人称・数。命令文や明示的主語のない不定詞では no_overt_subj。
💡 選択肢の意味と例(クリックで開閉)
1sg | 一人称単数。主語が "I"。例: "I understand the problem" / "I don't understand why". |
1pl | 一人称複数。主語が "we"。例: "We understand the difficulty" / "We hardly understand". 制度的・学術的な集合視点 ("we, the authors") を含む。 |
2 | 二人称 (特定の対話相手)。例: "Do you understand?" / "You understand French" (相手の能力について述べる)。※ 総称的な you は generic_you を選ぶ。 |
3sg | 三人称単数。代名詞 (he/she/it) や単数名詞句が主語。例: "She understands" / "The committee understands" / "The new policy is understood". 受動 "is understood" の主語が単数 NP の場合もここ。 |
3pl | 三人称複数。代名詞 (they) や複数名詞句が主語。例: "They understand" / "The members understand" / "Few people understand this". |
generic_one | 総称代名詞 "one"。書き言葉的・教導的に不特定の人を指す。例: "One can understand his frustration" / "How is one to understand this passage?". |
generic_you | 総称的 "you" (一般の「あなた」「人々」)。教導文・説明文に多い。例: "You can understand why she left" / "If you know X, you understand Y". ※ 特定の対話相手を指す "you" (= 2) と区別。文脈で総称読みになっているか確認。 |
impersonal_it | 非人称 "it" の認識構文。例: "It is understood that the meeting is postponed" / "It is widely understood that...". 受動構文と頻繁に共起。 |
no_overt_subj | 明示的主語なし。命令 ("Understand the rules")、to 不定詞 ("to understand the meaning", "easy to understand")、bare infinitive ("help me understand")、関係節の隠れた主語など。 |
F03 subj_animacy(主語の有生性):主語の意味的有生性。明示的主語がない場合は NA。
💡 選択肢の意味と例(クリックで開閉)
human_individual | 個別の人間。例: "John understands" / "Mary doesn't understand" / "my mother understood". 一人称・二人称代名詞 (I, you) もここに分類。 |
human_collective | 人間の集合体 (制度的でない)。例: "the team understands" / "the family understands" / "the audience understands". 集合的だが institution ほど公式ではないもの。 |
institution | 制度・組織主体。例: "the government understands" / "the company understands" / "Parliament has understood". 公式・法的・組織的な主体。 |
abstract | 抽象主体 (擬人化的用法)。例: "this theory understands" / "the law assumes / understands" / "common sense understands". 抽象概念が主語になる用法。 |
inanimate | 無生物 (機械・システム等)。例: "the program understands natural language" / "AI understands the query". 技術的文脈に多い。 |
NA | 主語なし (no_overt_subj に対応)。命令・不定詞等。 |
F04 subj_definiteness(主語の定性):主語名詞句の定性。代名詞は通常 definite。総称的なら generic。
💡 選択肢の意味と例(クリックで開閉)
definite | 定 (特定の指示対象)。代名詞 (I, we, you, he, she, it, they)、固有名詞 (John)、定冠詞付き (the council, the man)、所有格 (my mother) 等。例: "the council understands" / "John understands". |
indefinite | 不定 (非特定的)。不定冠詞付き (a friend, some people, an expert) 等。例: "a friend would understand" / "some people don't understand". |
generic | 総称 (種・類全体への言及)。bare plural、generic singular、総称的代名詞。例: "good teachers understand" / "anyone who knows X understands Y" / "one can understand". |
NA | 主語なし。 |
F05 obj_presence(目的語の有無):understand に明示的な目的語または補語があるか。NP・節・前置詞句・代名詞も含む。
💡 選択肢の意味と例(クリックで開閉)
yes | 目的語・補語あり。例: "understand the problem" (NP) / "understand that he left" (that 節) / "understand what he means" (wh 節) / "understand it" (代名詞) / "understand about him" (前置詞句). |
no | 絶対用法 (目的語なし)。例: 単独の "I understand." / "Yes, I understand." / 副詞だけで止まる "I fully understand". 応答トークン的用法に多い。 |
F06 obj_type(目的語のタイプ):目的語・補語の統語タイプ。判定は最も支配的なタイプ一つ。
💡 選択肢の意味と例(クリックで開閉)
NP | 名詞句。例: "understand the problem" / "understand French" / "understand his decision" / "understand her feelings". 普通名詞・固有名詞・動名詞 NP。 |
that_clause | that 節 (補文)。例: "understand that he's leaving" / "understand that the policy will change". that が省略されているケースも含む ("I understand he'll arrive early")。 |
wh_clause | wh 節。what/why/how/where/when を含む。例: "understand what he means" / "understand why she left" / "understand how the engine works". |
embedded_Q | 埋め込み疑問文 (yes/no 型)。例: "understand whether it works" / "understand if this is correct". ※ 埋め込み wh は wh_clause へ。 |
PP | 前置詞句が補語。例: "understand about him" / "understand X as Y" ("understand the term as a metaphor") / "understand from the report that...". categorization 用法に多い。 |
so_anaph | so 照応 (まれ)。例: "I understand so" / "I think so, I understand". 直前命題の参照。 |
it_anaph | it 照応。例: "I understand it" / "I don't understand it" — "it" が直前文・話題を参照。NP に分類しないでここを選ぶ。 |
nominal_clause | 動名詞節 (-ing 節)。例: "understand his leaving early" / "understand the children playing in the rain". -ing が補文として機能。 |
to_inf | to 不定詞補語 (慣用的)。例: "give to understand that..." / "be given to understand". 古風・法律的表現。 |
other | 上記いずれにも該当しない目的語タイプ。 |
none | 目的語なし (絶対用法)。例: "I understand." / "Yes, I understand." |
F07 tense(時制):understand の時制。定形 (finite) の場合に判定。不定詞や非定形 -ing は NA。
💡 選択肢の意味と例(クリックで開閉)
present | 現在形。例: "I understand" / "She understands" / "It is understood that...". |
past | 過去形。例: "I understood" / "She understood the answer" / "It was understood that...". |
future | 未来形 (will/shall + understand)。例: "You will understand later" / "I shall understand". ※ "going to understand" もここ。 |
present_perfect | 現在完了。例: "I have understood" / "She has finally understood" / "It has been understood". |
past_perfect | 過去完了。例: "I had understood" / "By then she had understood". |
NA | 非定形 (不定詞・補語位置の -ing 形等)。例: "to understand" / "can understand" / "easy to understand" / 動名詞 "understanding the issue". |
F08 aspect(相 (アスペクト)):動詞形のアスペクト。understand は状態動詞のため進行形は稀。
💡 選択肢の意味と例(クリックで開閉)
simple | 単純相 (基本)。例: "I understand" / "I understood" / "to understand". アスペクト標識なし。 |
progressive | 進行相 (be + -ing)。状態動詞のため稀だが、動的読み・段階的理解で出現。例: "I'm understanding the issue better now" / "He's slowly understanding the situation". |
perfect | 完了相 (have/has/had + understood)。例: "I have understood" / "She had understood by then" / "It has been understood". 受動完了も含む。 |
perfect_progressive | 完了進行相 (have been + understanding)。極めて稀。 |
F09 mood(法 (ムード)):understand を含む節の文法的ムード (主節レベル)。
💡 選択肢の意味と例(クリックで開閉)
declarative | 平叙 (基本)。事実・命題を述べる文。例: "I understand" / "She doesn't understand" / "It is understood that...". |
interrogative | 疑問。yes/no 疑問・wh 疑問・付加疑問。例: "Do you understand?" / "Why don't you understand?" / "You understand, don't you?". |
imperative | 命令。例: "Understand that..." / "Try to understand!" / "Don't misunderstand me". ※ 主語 you が省略されるのが特徴。 |
F10 polarity(極性):understand の極性 (肯定/否定)。否定標識 (not, n't, no, never, hardly, fail to, refuse to 等) で判定。
💡 選択肢の意味と例(クリックで開閉)
positive | 肯定。例: "I understand" / "She understands the problem" / "It is understood that...". 否定標識なし。 |
negative | 否定。例: "I don't understand" / "can't understand" / "failed to understand" / "never understood" / "refuse to understand" / "hardly understand" (※ hardly は否定極性を持つ). |
F11 voice(態):態 (能動/受動)。be + understood は受動。
💡 選択肢の意味と例(クリックで開閉)
active | 能動態 (基本)。例: "I understand the rules" / "She understood" / "can understand". |
passive | 受動態 (be/get + understood)。例: "It is understood that the meeting is postponed" / "The term is widely understood as..." / "His point was understood" / "to be understood". 認識の客観化用法に多い。 |
F12 clause_role(節の役割):understand を含む節が文中で果たす統語的役割。
💡 選択肢の意味と例(クリックで開閉)
matrix | 主節 (基本)。例: "I understand the problem." — understand が文の主動詞。 |
complement | 補文位置。例: "She said [I would understand]" / "They believe [people understand the rules]" — 上位節の補文として埋め込まれている。 |
relative | 関係節内。例: "the things [I understand]" / "a person [who understands the law]" — 名詞句を修飾する関係節。 |
adverbial | 副詞節内。例: "if [you understand], let me know" / "because [I understand the issue]" — 副詞的従属節。 |
coordinated | 等位接続節。例: "He listened and [understood]" / "She came in and [understood immediately]" — 等位接続詞 (and/but/or) で他節と接続。 |
parenthetical | 挿入句。例: "He's leaving, I understand, next week" / "She knows, you understand, what's at stake" — 文中に挿入される独立的なコメント。談話標識化していることが多い。 |
Layer 2:モダリティと副詞修飾(4 項目、F13–F16)
understand を修飾する助動詞と副詞の情報。"fully understand"、"can't quite understand" などの違いを捉える。
F13 modal(モーダル):understand に付くモーダル助動詞のタイプ。意味的に複数解釈可能なら最も支配的なものを。
💡 選択肢の意味と例(クリックで開閉)
epistemic | 認識的 (推量・確信)。例: "He must understand by now" (= きっと理解しているはず) / "may understand" / "might understand". 話者の確信度を示す。 |
deontic | 義務的 (命令・必要性)。例: "You should understand the rules" / "must understand (= 理解する必要がある)" / "ought to understand". 規範的義務。※ epistemic must との区別は文脈で。 |
ability_can | 能力 (can/could)。例: "can understand" / "could understand" / "could not understand". ※ "I can understand your frustration" のような empathic 用法もここに分類 (形態的には能力モーダル)。 |
volitional | 意志・予測 (will/would/shall)。例: "You will understand later" / "They would understand if we explained" / "I shall understand". |
none | モーダルなし。例: "I understand" / "She understood". be going to は volitional に含めるか none か文脈で判断、迷ったら none。 |
F14 pre_adverb_type(前置副詞のタイプ):understand の直前または近傍にある副詞のタイプ。複数あれば understand を直接修飾する最も主要なものを選ぶ。
💡 選択肢の意味と例(クリックで開閉)
degree | 程度副詞。例: "completely understand" / "fully understand" / "partially understand" / "thoroughly understood". 理解の達成度を表す。 |
negation_partial | 部分否定的副詞。例: "hardly understand" / "barely understand" / "scarcely understood". 否定極性を持つが完全否定ではない。 |
manner | 様態副詞。例: "well understand" / "poorly understood" / "clearly understand" / "vaguely understand". 理解の質を表す。 |
focus | 焦点化副詞。例: "just understand" / "only understood" / "even understand". 命題の焦点を絞る。 |
none | 前置副詞なし。 |
F15 degree_adv_lex(程度副詞の語彙):F14 が degree の場合、その具体語彙を選ぶ。F14 が degree 以外なら NA。
💡 選択肢の意味と例(クリックで開閉)
completely | completely (完全に)。例: "I completely understand". |
fully | fully (十分に・完全に)。例: "fully understand" / "fully understood". |
really | really (本当に)。例: "I really understand what you mean". |
well | well (よく)。例: "I well understand your concern" / "well understood". |
hardly | hardly (ほとんど〜ない、部分否定)。例: "hardly understand" / "hardly understood". |
barely | barely (かろうじて〜、部分否定)。例: "barely understand". |
quite | quite (かなり)。例: "I quite understand". (BrE) |
sort_of | sort of (なんとなく、ヘッジ)。例: "I sort of understand". |
kind_of | kind of (なんとなく、ヘッジ)。例: "I kind of understand". |
other | 上記以外の程度・修飾副詞。 |
NA | F14 が degree でない、または前置副詞なし。 |
F16 negation_scope(否定の作用域):極性が否定 (F10=negative) の場合、否定の作用域。否定が動作全体か一部かを判定。F10=positive なら NA。
💡 選択肢の意味と例(クリックで開閉)
full | 全否定。例: "I don't understand" / "I can't understand" / "I never understood" / "don't understand at all". understand の動作・状態全体が否定される。 |
partial | 部分否定。例: "I don't fully understand" / "don't completely understand" / "hardly understand" — 程度副詞・否定極性語彙との組み合わせで一部だけ否定される。 |
NA | 肯定文 (F10=positive)。 |
Layer 3:目的語の意味類型(4 項目、F17–F20、F05=yes のときのみ)
何を understand するのかという「対象」の意味分類。"understand the equation"(メカニズム)と "understand your feelings"(人物の感情)は異なる意味次元に属する。
F17 obj_semclass(目的語の意味クラス):目的語が指す内容の意味クラス。複数解釈ありうる場合は最も支配的なものを。F05=no なら NA。
💡 選択肢の意味と例(クリックで開閉)
proposition | 命題的内容 (真偽値を持つ事実・主張)。例: "understand that he's leaving" / "understand the fact that..." / "It is understood that..." — that 節や命題的 NP が中心。 |
instructional | 指示・実践的内容。例: "understand the instructions" / "understand the rules" / "understand the procedure" — 行動指針・方法論。 |
language_code | 言語コード。例: "understand French" / "understand the dialect" / "understand sign language" — 言語そのものを理解する。 |
abstract_concept | 抽象概念・主義。例: "understand democracy" / "understand the meaning of life" / "understand the theory" / "understand love" — 抽象的観念。 |
mechanism | 仕組み・原理・プロセス。例: "understand how the engine works" / "understand the process" / "understand the mechanism" — 動的な仕組み。 |
person_feeling | 人の感情。例: "understand your feelings" / "understand how you feel" / "understand his pain" — 感情への共感。empathy 用法の中心。 |
person_situation | 人の状況・境遇。例: "understand your situation" / "understand his predicament" / "understand what you're going through" — 個人的境遇への理解。empathy 用法でもある。 |
event_situation | 出来事・事象。例: "understand what happened" / "understand the war" / "understand the crisis" — 客観的な出来事。person_situation と区別: 個人化されていれば person_situation、客観的事象なら event_situation。 |
metalinguistic | メタ言語的解釈。例: "understand 'tort' to mean breach of duty" / "understand the term as a metaphor" / "understand X in the sense of Y" — 用語・記号の解釈。categorization 用法。 |
NA | 目的語なし (F05=no)。 |
F18 obj_referent(目的語の指示対象):目的語が指す対象の指示タイプ。F18 は対人配慮 (Empathy) 用法の検出に重要。
💡 選択肢の意味と例(クリックで開閉)
addressee | 対話相手 (you/your X)。例: "understand your feelings" / "understand you" / "understand your point" — Empathy / alignment 用法の中心的指標。 |
self | 自己 (me/my X)。例: "understand my own motives" / "understand myself" — 内省的用法。 |
third_party | 第三者 (him/her/their X)。例: "understand his decision" / "understand her feelings" / "understand them". |
generic | 総称・一般。例: "understand human nature" / "understand people" / "understand anyone in this situation". |
non_human | 非人間的対象。例: "understand the theory" / "understand the process" / "understand French" — 概念・出来事・物事。person_feeling 等と区別。 |
NA | 目的語なし。 |
F19 obj_complexity(目的語の複雑性):目的語が単純句か、内部に節を含む複合構造か。
💡 選択肢の意味と例(クリックで開閉)
simple | 単純句。例: "the problem" / "his decision" / "French" / "that p" (単一補文)。修飾句があっても節を含まない。 |
complex | 複雑構造 (節を含む)。例: "that despite all the difficulties he had faced, the project would succeed" / "how the system she had designed actually worked in practice" — 内部に複数の節・修飾節を含む。 |
NA | 目的語なし。 |
F20 obj_referentiality(目的語の指示性):目的語の指示の特定度。文脈中の特定の対象か、総称か、仮定の対象か。
💡 選択肢の意味と例(クリックで開閉)
specific | 特定指示 (文脈中の identifiable な対象)。例: "understand THIS problem" / "understand the answer (we discussed)" / "understand his decision (about the merger)". |
generic | 総称的 (種・類全般)。例: "understand problems (in general)" / "understand human nature" / "understand languages". 不定単数や定の総称。 |
hypothetical | 仮想的・条件的。例: "if I were to understand X" / "trying to understand a possible solution" / "to understand any difficulty that might arise". |
NA | 目的語なし。 |
Layer 4:共起語彙(3 項目、F21–F23)
対象文中で understand の前後 10 語以内に現れる語彙的手がかり。ヘッジ・情意語・証拠性表示がどれくらい一緒に現れるかを観察する。
F21 co_hedge(ヘッジの共起):同一文内 (±10 トークン程度) に認識的ヘッジ表現が共起しているか。話者の確信度を緩和する語句。
💡 選択肢の意味と例(クリックで開閉)
yes | ヘッジあり。例: "I think I understand" / "I suppose she understands" / "I sort of understand" / "You know, I understand" / "I guess he understands" / "I mean, do you understand?" / "kind of understand" / 認識動詞 (think, suppose, guess, reckon) 等が共起。 |
no | ヘッジなし。 |
F22 co_affective(感情語彙の共起):同一文内に感情・情動関連の語彙が共起しているか。Empathy 用法の主要指標。
💡 選択肢の意味と例(クリックで開閉)
yes | 感情語彙あり。例: "I understand your feelings" (feelings) / "I understand the pain you've been through" (pain) / "I can understand your frustration" (frustration) / "I understand your concerns" (concerns) / "I understand what you're going through" (going through, situation as predicament). hurt, sad, angry, worried, anxious 等の感情語も含む。 |
no | 感情語彙なし。例: "I understand the rules" / "He understands French" — 中立的・命題的内容のみ。 |
F23 co_evidential(証拠標識の共起):同一文内に証拠標識 (情報源・伝聞性を示す表現) が共起しているか。認識の根拠を示す。
💡 選択肢の意味と例(クリックで開閉)
yes | 証拠標識あり。例: "apparently he understands" (apparently) / "It seems she understood" (it seems) / "As far as I know, he understands" (as far as I know) / "I gather they understood" (I gather) / "I'm told they understand" (I'm told) / "reportedly understood" (reportedly) / "allegedly understood". |
no | 証拠標識なし。 |
Layer 5:談話・語用論(4 項目、F24–F27、最も判定が難しい層)
"I understand." が独立した応答トークン(response token)として使われる用法と、"Do you understand?" が理解確認(comprehension check)として使われる用法を区別する、もっとも解釈的なレイヤー。前後文脈と組み合わせて判定する。
F24 speaker_perspective(話者視点):誰の認識状態が前景化 (foregrounded) されているか — 機能的観点。形態的な F02 主語人称とは区別: F02 は文法形式、F24 は焦点化される認識主体。
💡 選択肢の意味と例(クリックで開閉)
1st_person | 話者自身の認識を焦点化。例: "I understand X" — 話者の認識が中心。"I think we understand" のような we も話者を含むので一人称的。 |
2nd_to_addressee | 対話相手の認識を焦点化。例: "you understand X" / "do you understand?" / "You will understand later" — 相手の認識が話題。 |
3rd_person_report | 第三者の認識を報告。例: "she understands" / "the committee understands" / "few people understand this" — 観察者視点で他者の認識を述べる。 |
impersonal | 非人称・客観化。例: "It is understood that..." / "It is widely understood" — 認識の主体が消去され、社会的・公的な共有知識として表現される。 |
F25 speech_act_function(発話行為機能):発話行為としての主機能 (相互行為的解釈)。書き言葉のモノローグ・客観的命題報告は通常 information_report または NA。
💡 選択肢の意味と例(クリックで開閉)
information_report | 情報報告 (基本)。例: "He understands French" / "She didn't understand the question" / "It is understood that the meeting is postponed" — 客観的に認識状態を記述。書き言葉散文の大半。 |
claim_of_knowledge | 知識主張。例: "I understand the situation perfectly" / "We fully understand what's at stake" / "I understand exactly what you mean" — 自分の理解を強く主張する用法 (情報伝達の枠を超えた知識顕示)。 |
alignment | 同調 (相手への共感・連帯)。例: "I understand how you feel" / "I understand your frustration" / "I can understand your reluctance" — 相手の感情・状況に明示的に寄り添う。Empathy 用法の中核。 |
comprehension_check | 理解確認。例: "Do you understand?" / "Did you understand what I said?" / "You understand, don't you?" — 相手の理解度を確認する疑問。 |
response_token | 応答トークン (相槌的)。例: 単独の "I understand." (相手の発話を受けて) / "Right, I understand." / "Oh, I understand now." — 対話の流れで相手への受容を示す短い応答。 |
hedge | 緩和 (parenthetical 的)。例: "He's leaving, you understand, next week" / "It was, I understand, a difficult decision" — 文中挿入の "you understand" / "I understand" は談話標識として柔らかさを加える。 |
mitigation | 面子配慮的緩和。例: "I understand if you don't want to talk about it" / "I would understand if you refused" — 相手の選択肢を尊重する丁寧表現。 |
NA | モノローグ書き言葉等で対人機能が不明・該当しない場合。 |
F26 epistemic_stance(認識的立場):この用法で示される認識的立場 (確信度・情報源)。F21 (ヘッジ共起) と F23 (証拠標識共起) に連動するが、より統合的な判断。
💡 選択肢の意味と例(クリックで開閉)
assertive | 断定的 (確信ある主張)。例: "I understand the rules" / "She fully understands" — ヘッジなしの直接的認識主張。 |
hedged | ヘッジ付き (不確実性緩和)。例: "I think I understand" / "I sort of understand" / "I guess he understands" / "I might understand later" — 認識の確実性が緩められる。 |
evidential | 証拠的 (情報源標示)。例: "It is understood that..." / "As I understand it, ..." / "I gather they understand" / "apparently he understands" — 情報源・伝聞性が表に出る。 |
NA | 該当なし (判定困難な場合)。 |
F27 sequential_position(連鎖上の位置):前後文脈との関係における発話の位置づけ (連鎖分析的観点)。サイドバーの prev_sent と next_sent を参照して判定。
💡 選択肢の意味と例(クリックで開閉)
response_to_prior | 直前発話への応答。例: A: "It's been hard." B: "I understand." / 直前文の主張・問題提起に対する反応。話し言葉のターンのみならず、書き言葉でも直前命題への応答 ("Indeed, I understand his point") を含む。 |
initiation | 新しい話題・問いの開始。例: "Do you understand the implications?" (会話冒頭) / "To understand this, we must consider..." — 新しいトピックを切り出す。 |
continuation | 自分自身の発話の継続。例: 同一話者の発話内・段落内で連続する命題の一部 — "I see what you mean. I understand the issue. But..." の中央。 |
monologic | 対話文脈なし。例: 書き言葉の散文・論文・物語で、対話のターンが存在しない場合。本データの大半 (書き言葉) は monologic。 |
NA | 文脈が不明・判定困難。 |
判定例(実際のアノテーション・ガイドラインより)
- ・Do you understand?(対話中、単独で)→ F09=interrogative、F25=comprehension_check、F27=initiation
- ・I understand.(単独の応答トークン)→ F05=no、F25=response_token、F27=response_to_prior
- ・I understand your feelings. → F18=addressee、F22=yes、F25=alignment
- ・It is understood that the Minister will resign. → F11=passive、F02=impersonal_it、F26=evidential
- ・She didn't understand the equation. → F10=negative、F17=mechanism or abstract_concept
人手アノテーションと AI アノテーション
27 項目の素性スキーマを設計したあと、実際に各用例にラベルを付けていく作業をアノテーション(注釈付け)と呼びます。BP 分析の妥当性は、このアノテーションの精度に大きく依存します。アノテーションには大きく二つのやり方があります。
伝統的な手法:人手アノテーション
BP 分析が方法論として確立された当初から行われてきた、もっとも標準的なやり方は、訓練を受けた複数のアノテーターによる人手注釈です。手順は次のようになります:
- アノテーター(多くの場合、言語学の大学院生・研究員)に対して、素性スキーマと判定マニュアルを共有する
- パイロット用例(数十件程度)で訓練と意見すり合わせを行う
- 本番の用例について、二人以上のアノテーターが独立にすべての素性を付与する
- 項目ごとに Cohen's κ(カッパ係数)でアノテーター間一致度を算出する
- κ < 0.6 の項目は定義を見直すか、本分析から除外する(信頼性が確保できないため)
- 不一致用例は協議で最終ラベルを確定する
この方法は妥当性が高い一方、時間とコストが膨大です。一件あたり 5〜10 分かかるとすれば、1,000 件を 27 項目で二人が独立に注釈するだけで延べ 300 時間以上を要します。BP 研究が長らく数百件規模のサンプルに留まり、コーパス全件規模の分析になかなか踏み出せなかったのはこの制約のためです。
現代的な手法:LLM(大規模言語モデル)によるアノテーション
2023 年以降、Claude / GPT / Gemini といった大規模言語モデル(LLM)が言語学的注釈の作業を高い精度でこなせることが分かってきました。これによって BP 分析のスケールが劇的に変わりつつあります。
understand プロジェクトでは、次のような multi-model + human validation 方式を採用しています:
- 同じ素性スキーマと判定マニュアルをプロンプトとして LLM に与える。Structured Output(tool use)機能を使い、LLM が必ず 27 項目の決められた選択肢から出力するよう制約する
- 各用例について 複数の LLM(Claude / GPT / Gemini)に独立に注釈させる
- モデル間で一致した項目は信頼度が高いとみなす(self-consistency)
- 200 件程度をサンプリングし、人間の専門家がゴールドスタンダードとして注釈する
- 項目ごとに LLM–人間の κ を算出し、各モデル・各項目の信頼性を可視化する
- 信頼性の低い項目はプロンプト改訂・スキーマ改訂・あるいは人手検証の追加投入で補強する
経験的には、Layer 1–2(形態統語・モダリティ)は LLM の判定精度がほぼ人間並み(κ > 0.8)、Layer 3–4(意味・共起)は中程度(κ ≈ 0.6–0.8)、Layer 5(談話・語用)はもっとも難しく、項目によっては LLM 単独では不十分で人手検証を厚くする必要があります。
重要なのは、AI アノテーションは人手アノテーションを完全に置き換えるものではないという点です。むしろ、人手アノテーションを「検証用ゴールドスタンダード」として残しつつ、LLM で規模を BNC 全件レベルにまで拡大する──この補完的な役割分担が、現代のコーパス言語学における BP 分析の主流になりつつあります。人文学研究者にとっての含意は明確です。これまでは「興味深いが現実的に手が出ない」と諦めていた規模の言語データに対して、研究者が定義した理論的素性スキーマを忠実に適用しながら定量的に分析することが、はじめて可能になりつつあるのです。
関連研究:explain の Behavioral Profile 分析(Sugawara & Kambara 2023)
続いて、ここまで論じてきた Behavioral Profile(BP)分析を、英語動詞 explain に適用した具体的な先行研究を紹介します。Sugawara & Kambara (2023) "The Many Uses of Explain: Quantitative Corpus Method and Philosophy of Science"(『科学基礎論研究』Annals of the Japan Association for Philosophy of Science Vol.32, pp.23–46)は、BNC から explain の用例 657 件を手作業で多次元注釈し、HCA + 対応分析(CA)+ ロジスティック回帰を組み合わせて分析したものです。フレーム意味論を素性スキーマの中核に据えた点が方法論的に特徴的で、続く 6.11 の Sugawara (2026, DCA) はこの研究の知見と限界を踏まえて埋め込みベース手法へ発展させたものです。本節では論文中の Figure 3–6 を実際に見ながら、古典的 BP 分析の輪郭を確認していきます。
研究の問い:科学哲学とコーパス言語学の橋渡し
科学哲学は伝統的に「ケーススタディ法」──著名な科学文献を精読しながら「説明とは何か」を内省的に考える方法──を用いてきましたが、Machery (2016) はそのバイアスを批判し、大規模な言語データに基づく実験的科学哲学を提唱しました。Overton (2013) はこの問題意識から「explain in scientific discourse」というコーパス研究を行い、科学論文中の用例頻度を集計しました。
しかしながら、Overton の研究には次のような限界がありました:(i) 対象を科学論文に限定したため、日常的・制度的な用法が観察できない、(ii) 単語の頻度を集計するだけで、語の多義性(polysemy)を扱えない、(iii) ランダムサンプリングの代表性に疑問。Sugawara & Kambara (2023) はこれらを乗り越えるため、均衡コーパスである BNC からのランダム抽出 + フレーム意味論ベースの手作業注釈 + 多変量統計という枠組みを採用しました。
なお、本研究は方法論的に仮説駆動型(hypothesis-driven)の BP 分析として位置づけられる点に注意してください。研究者があらかじめ「explain には Explaining₁(コミュニケーション的副フレーム)と Explaining₂(科学的副フレーム)という 2 つの下位フレームがある」という理論的仮説を立て、その仮説を反映する形で注釈項目(フレーム要素・文法素性)を設計してからアノテーションを行い、最後に多変量解析でその仮説がデータに支持されるかを検証する──という流れになっています。これは 6.5 で扱った Corpus-based(コーパス検証型)アプローチの典型例であり、データのなかから事前理論なしにカテゴリを発見しに行く Corpus-driven(コーパス駆動型)アプローチ(6.11 の DCA がそちらに近い)とは、設計思想が対照的です。
データと注釈スキーマ
データ:BNC から explain の動詞用例 6,570 件を Sketch Engine で抽出し、ランダムに 10%(657 件)を分析対象としました。
注釈スキーマは 3 層から構成されています:
- ・(1) フレーム意味論アノテーション:FrameNet 流のフレーム=フレーム要素分析を採用。explain が喚起する
Explainingフレームを 2 つの下位フレームに分けて記述:- ―
Explaining₁(コミュニケーション的 / 「ordinal」な説明):⟨Explainer⟩(説明者:人間)が ⟨Topic⟩(話題)を、しばしば ⟨Audience⟩(聴衆)に、⟨Medium⟩(媒介)を通じて伝達する。 - ―
Explaining₂(科学的説明):⟨Explanan⟩(説明項:通常は無生物の要因)が ⟨Explanandum⟩(被説明項:現象)の特徴を捉える。
- ―
- ・(2) 文法素性(4 つの二値素性):
isPassive(受動態か)、Modality(命令文か)、Quotation(引用を含むか)、Explicit⟨Explainer⟩(説明者が明示的に実現されているか)。 - ・(3) ジャンル素性:BNC の 10 ジャンル(Applied science / Arts / Belief & thought / Commerce & finance / Imaginative / Leisure / Natural & pure science / Social science / Unknown / World affairs)。
フレーム要素の実現組み合わせ(サブアレイ subarray)として Ed, En+Ed, Top, Top+Med, Aud+Top, Exp+Top, Exp+Top+Med, Exp+Aud+Top, Exp+Aud+Top+Med の 9 種類を識別し、それぞれの分布を多変量解析にかけています。
統計手法:HCA × CA × ロジスティック回帰の三段構え
本研究は単一の手法ではなく、3 種類の多変量解析を相補的に用います(6.7 の「統計解析の選択肢」で挙げた手法のうち、HCA・CA・ロジスティック回帰の併用例として典型的):
- 階層クラスター分析(HCA):サブアレイ × 素性のクロス集計表に対して、Canberra 距離 + Ward 法でクラスタリング。さらに
pvclust系のmultiscale bootstrap resampling で p 値(AU = Approximately Unbiased、BP = Bootstrap Probability)を算出し、クラスターの統計的支持を可視化。 - 対応分析(CA):同じクロス集計表を主軸分解し、サブアレイ(赤)と素性(青)を二次元平面に同時布置。各クラスターを「どの素性が形成に寄与しているか」のかたちで解釈可能にする。
- ロジスティック回帰:「⟨Explainer⟩ が実現されているか/否か」を応答変数、ジャンルが学術的(academic)か非学術的(non-academic)かを説明変数とする二項回帰モデルで、「説明者の言語的明示性」がジャンルとどう関連するかを統計的有意性込みで示す。
HCA は用例の構造化に、CA は構造の意味づけに、ロジスティック回帰は仮説の確認に、それぞれ役割が振り分けられている点に注目してください。
Figure 3:文法素性の HCA + CA
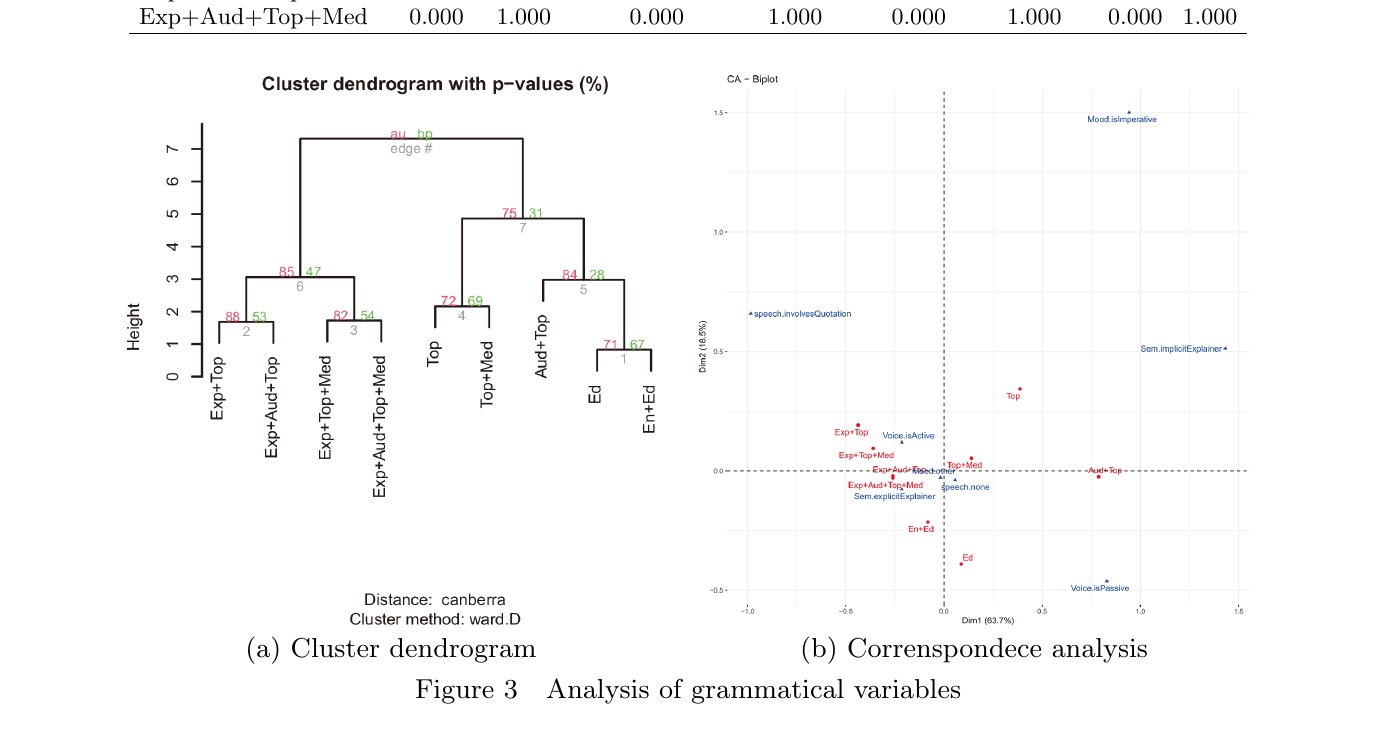
文法素性だけを用いた解析結果が Figure 3 です。左の樹形図では、⟨Explainer⟩ を含むサブアレイ(Exp+Top, Exp+Aud+Top, Exp+Top+Med, Exp+Aud+Top+Med)が左側に、⟨Explainer⟩ を含まないサブアレイ(Top, Top+Med, Aud+Top, Ed, En+Ed)が右側に分かれます。右の CA バイプロットでは、左半分に Voice.isActive と Sem.explicitExplainer が集まり、右半分に Voice.isPassive と Sem.implicitExplainer、上方に speech.involvesQuotation、右上に Mood.isImperative が布置されます。すなわち、「⟨Explainer⟩ の有無が、能動/受動・明示/非明示と緊密に連動している」ことが視覚的に確認できます。
Figure 4:ジャンル素性の HCA + CA
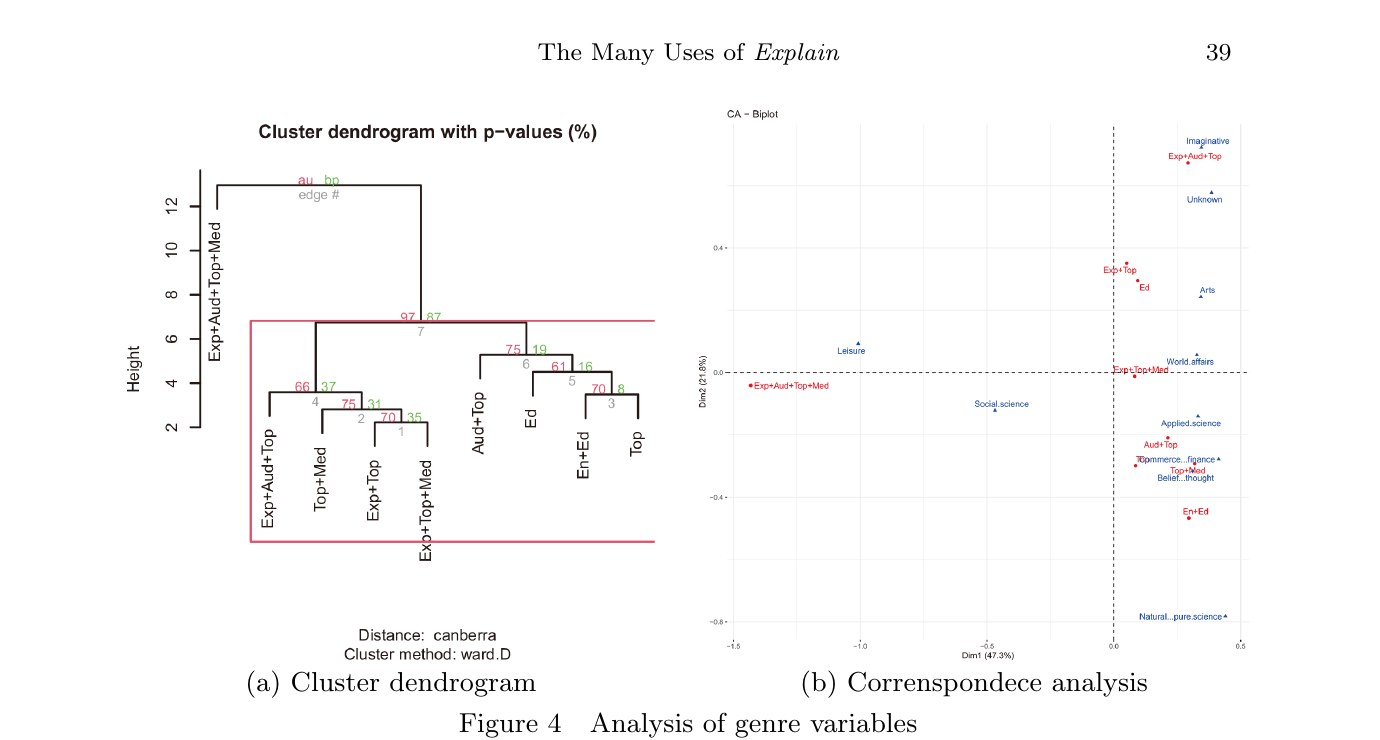
ジャンル素性だけを用いた解析が Figure 4 です。樹形図では、Exp+Aud+Top+Med が一つだけ離れて出現し、残りのサブアレイが p < 0.05 で有意な大クラスターを作ります(左の赤枠)。CA バイプロットでは、⟨Explainer⟩ を含むサブアレイ(赤)が左上=Imaginative / Unknown / Arts / Leisure などの非学術ジャンル側に、⟨Explainer⟩ を含まないサブアレイ(En+Ed, Aud+Top, Top+Med 等)が右下=Natural & pure science / Applied science / Commerce & finance / Belief & thought / World affairs などの学術ジャンル側に分かれて布置されます。つまり、「explain の使い方はジャンルによって組織立って異なる」──物語的ジャンルでは「誰が誰に説明したか」を語り、科学的ジャンルでは「何が何を説明するか」を語る、というはっきりとした分業が観察されたのです。
Figure 5:文法素性 + ジャンル素性を統合した解析
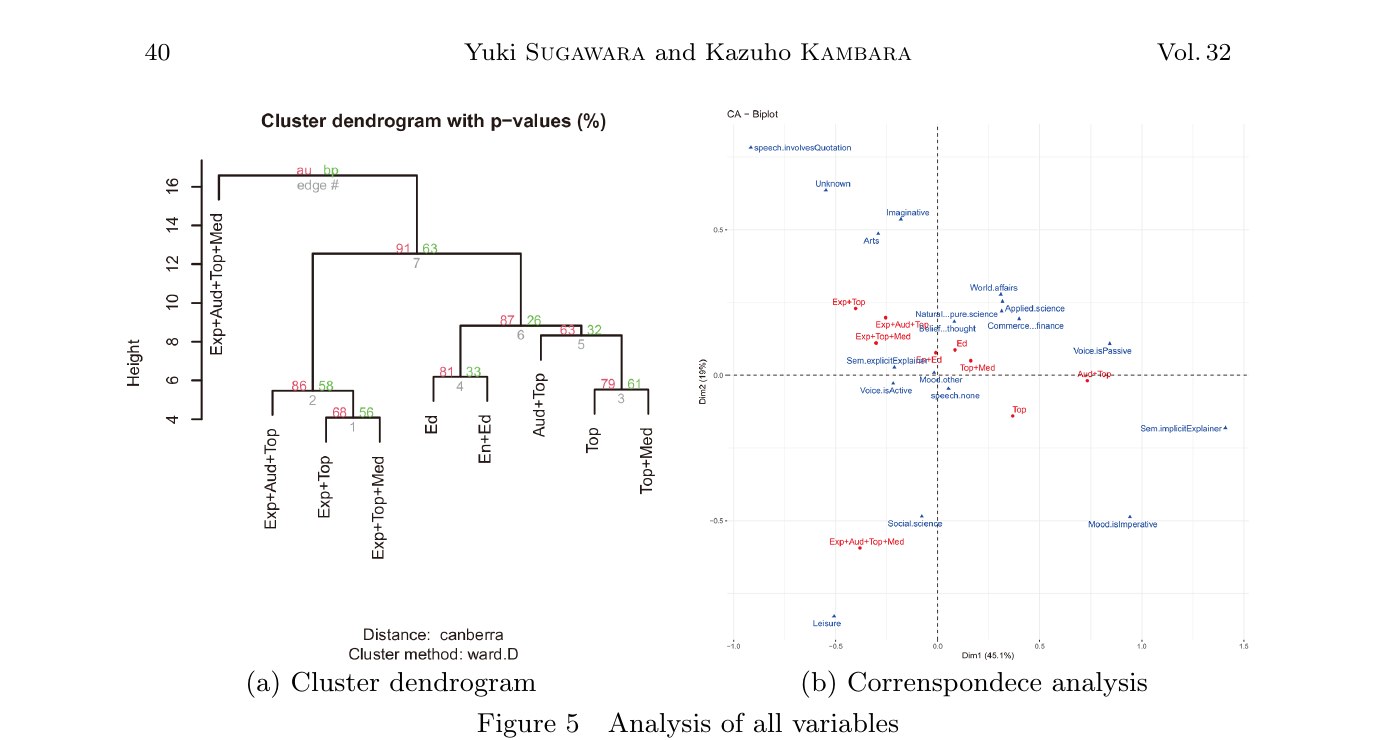
Figure 5 は文法素性とジャンル素性を一緒に投入した結果です。樹形図ではやはり ⟨Explainer⟩ 有無の二分が支配的──左に Exp+Aud+Top / Exp+Top / Exp+Top+Med、右に Ed / En+Ed / Aud+Top / Top / Top+Med。CA バイプロットでは、左上に speech.involvesQuotation と Unknown / Imaginative / Arts、左下に Exp+Aud+Top+Med・Social science・Leisure、右側に Natural / Applied / Belief / Commerce / World affairs と Voice.isPassive・Sem.implicitExplainer がそれぞれ集まります。⟨Explainer⟩ の有無という単純な軸が、文法的特徴(能動・受動、明示・非明示)とジャンル(非学術・学術)の両方を貫通して同時に組織化していることが、この一枚の図から読み取れます。
Figure 6:モザイク図と ロジスティック回帰の効果プロット
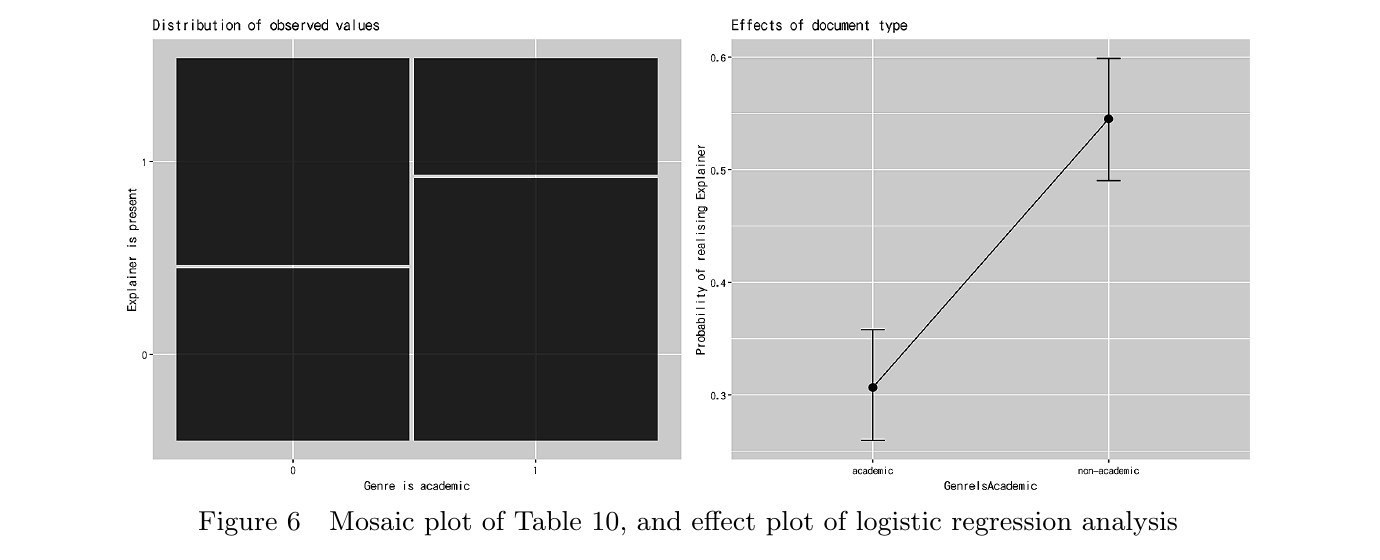
HCA・CA で観察されたジャンル × ⟨Explainer⟩ の関係を、統計的に確認したのが Figure 6 です。左のモザイク図は、ジャンルが学術的(1)/ 非学術的(0)と、⟨Explainer⟩ が実現されているか(1)/ いないか(0)の 4 セルの観察頻度を面積で示します。右の効果プロットは、ロジスティック回帰モデルから推定された「⟨Explainer⟩ が実現される確率」を、95% 信頼区間とともに描いたもの。学術ジャンルでは確率 0.307、非学術ジャンルでは 0.547と推定され、その差は p = 9.35 × 10⁻¹⁰(係数 −0.998、SE = 0.163、z = −6.12)と極めて高い有意性を示しました。「explain は学術的な文章ほど『何が説明するか』を主語にし、非学術的な文章ほど『誰が説明するか』を主語にする」という傾向が、数値的・確率的にも裏付けられたのです。
質的観察:差異化パターンと引用用法
量的分析に加えて、論文は次のような質的な発見も報告しています:
- ・⟨Explainer⟩ と ⟨Explanan⟩ の差異化:両者の文法的主語の有生性(sentient か否か)がはっきり対照的。
例: "Now he says he wrote to S & N chairman, Alec Rankin, asking him⟨Explainer⟩ to explain fully the reasons for switching away from diesel⟨Topic⟩."(コミュニケーション的)
vs. "Several geological factors⟨Explanan⟩ may explain this apparent discrepancy⟨Explanandum⟩."(科学的) - ・引用用法(quotative use):"You must understand," explained Mrs Puri のような引用付き用法(n = 52)はすべて文法的目的語の前置を伴うという形式的特徴を共有していた(=「報告動詞としての explain」の構造的シグネチャ)。
これらは、量的に浮かび上がったクラスター構造に対し、個別用例の精読によって「なぜそのクラスターが形成されたか」を裏打ちする定性的な作業の重要性も示しています。
哲学的含意:QCM × 科学哲学
Sugawara & Kambara (2023) はこの分析を通じて、次の哲学的主張を行います:
- ・科学哲学で語られてきた「説明(explanation)」概念は、自然言語の explain のうちの Explaining₂(科学的副フレーム)に偏ったサブセットだった。Explaining₁ のコミュニケーション的用法を「説明」概念から排除する根拠はない。
- ・Overton (2013) のようなテキストマイニング + ランダムサンプリングでも頻度は集計できるが、語の多義性は捉えられない。フレーム意味論ベースの注釈 + 多変量統計を組み合わせることで、はじめて「説明」概念の下位構造が見えてくる。
- ・Dennett の議論を引きながら、「我々がどう explain するか」と「explain がそもそも何か」は認識論(epistemology)と存在論(ontology)の不可分性を示している。BP 分析はこの両者をつなぐ橋となりうる。
- ・哲学者の伝統的なケーススタディ法に対する「Quantitative Corpus Method(QCM)」は、科学哲学の「自然化(naturalization)」──Quine 流の認識論の自然化を概念分析に拡張する試み──の一翼を担う。
Sugawara 2026(DCA, 6.11)との関係:BP から DCA への系譜
この 2023 年論文(Sugawara & Kambara)は、657 件の手作業注釈に基づく古典的 BP 分析を貫徹した研究です。その限界としては、(i) 規模が 657 件と限定的、(ii) フレーム素性の定義が研究者の理論的選択に依存、(iii) 連続的・分布的な意味変動を捉えにくい、といった点が残りました。次節 6.11 で紹介する Sugawara (2026) の Distributional Concept Analysis(DCA)は、これらの限界を 文埋め込み + UMAP + PCA + CTM + GPT-5 ラベリングで克服しようとした続編にあたります。2023 年論文で「2 つの subframe(Explaining₁ / Explaining₂)に分かれる」と論じられた構造が、2026 年論文では「6 つの説明 constellation が連続的に布置される銀河構造」へと展開していくわけです。BP(記号的・離散的)から DCA(分布的・連続的)への移行は、コーパス研究の手法的進化を象徴的に示しています。
この研究は、人文学(言語学・哲学)が統計手法を「使う」だけの研究から、複数の統計手法を相補的に組み合わせて深い解釈を導く研究へと進化していることの好例です。HCA は構造を見出し、CA はその意味を可視化し、ロジスティック回帰は仮説を確証する──各手法が役割を分担しながら、explain という一つの動詞のなかに眠る言語的・哲学的構造を浮かび上がらせています。
📦 データと再現性:本研究の注釈済みデータセットと R 統計解析コードはすべて Open Science Framework(OSF)上で公開されています:
https://osf.io/znr7x/?view_only=5cfebf52ca4d4546b7594432b7051551
論文本体は CC BY-NC-ND 4.0 で公開されています(Annals of the Japan Association for Philosophy of Science Vol.32, pp.23–46, 2023)。
関連研究:explain の Distributional Concept Analysis
コーパスを用いた語の意味分析には、BP 分析以外にも様々な手法があります。ここでは関連研究として、英語動詞 explain を対象とした筆者の研究 Sugawara (2026) "Distributional Concept Analysis of Explain: From Distant Reading to Cosmic Reading"(『英語コーパス研究』第33号)を、論文中の図 1〜6 を実際に見ながら紹介します。BP 分析と対比することで、現代コーパス研究の方法論的な広がりがよく見えるはずです。
研究の問い
「説明する(explain)」とは、自然言語のなかで実際にどのような行為として現れているのか? 科学哲学では Hempel & Oppenheim (1948) の演繹的法則的モデル(deductive-nomological model)、Salmon (1984) の因果機構説(causal–mechanistic account)、van Fraassen (1980) の語用論的説明論(pragmatic theory)、Machamer–Darden–Craver (2000) のメカニズム説(mechanistic model)など多くの理論が提案されてきましたが、これらは「説明とは何を説明することか」についての前提が互いに異なり、自然言語のなかで explain がどう現れているかを統一的に捉えていません。Overton (2013) はこの問題意識から「explain in scientific discourse」というコーパス研究を行いましたが、対象は科学論文に限られていました。本研究はその対象を BNC 全体(科学・物語・制度・対話など全ジャンル)に拡張し、コーパスデータから定量的かつ分布的に説明実践の多様性を明らかにすることを目指します。
理論的背景:distant reading から cosmic reading へ
本研究は分布意味論(distributional semantics, Lenci 2018)に基づき、語の「意味」と「機能」を次のように操作的に定義します:
- ・意味(meaning)=高次元意味空間における共起分布の総体。すなわち、その語が現れる文脈の全体的なパターン。
- ・機能(function)=特定の談話文脈における語用論的・コミュニケーション的役割。文脈化された埋め込みは、語が働く言説環境を構造的にエンコードする。
この立場は、Moretti (2013) の distant reading(遠読)──個々のテキストを精読するのではなく、大規模コーパスの構造的・分布的パターンを観察するアプローチ──の延長線上にあります。ただし distant reading は語の頻度やジャンル分布など表層的な指標に焦点を当てがちで、より深い「意味的分布」を捉えるには不十分でした。
本研究では、文単位の文脈化埋め込み・確率的トピックモデル・LLM を統合することで、語の「意味的地形(semantic topography)」そのものを観察可能にする手法を提案し、これを cosmic reading(宇宙的読解)と名づけます。テキストを「離れて眺める」だけでなく、テキストが埋め込まれた高次元意味空間を「銀河」として観察し、クラスター・帯・空隙・「星座」を読み解く──これが distant reading から cosmic reading への方法論的なシフトです。さらに Machery (2016) の experimental philosophy of science(実験的科学哲学)の主張、すなわち「概念使用の多様性は大規模な言語・行動データで実証されるべき」とも理論的に接続します。
データと方法
BNC から Sketch Engine を使って explain の KWIC 用例を 18,664 件抽出し、ランダムサンプリングで 10,000 件を分析対象としました。そこに Distributional Concept Analysis(DCA)と呼ばれる 5 層パイプラインを適用します:
- 文埋め込みによる意味空間の構築:E5-large-v2 モデルで各文を 1,024 次元のベクトルに変換
- UMAP による「意味銀河」の可視化:高次元空間を 2 次元に投影し、用例の分布を観察
- PCA による意味軸の抽出:大域的な意味変動軸(科学的↔物語的、制度的↔対人的など)を主成分として抽出
- CTM(Combined Topic Model)による潜在トピック推定:50 個の意味的に整合的なトピックを抽出
- GPT-5 による概念ラベル付け:統計的トピックを人間が解釈可能な概念単位に変換
Figure 1:意味銀河(ジャンル色分け)
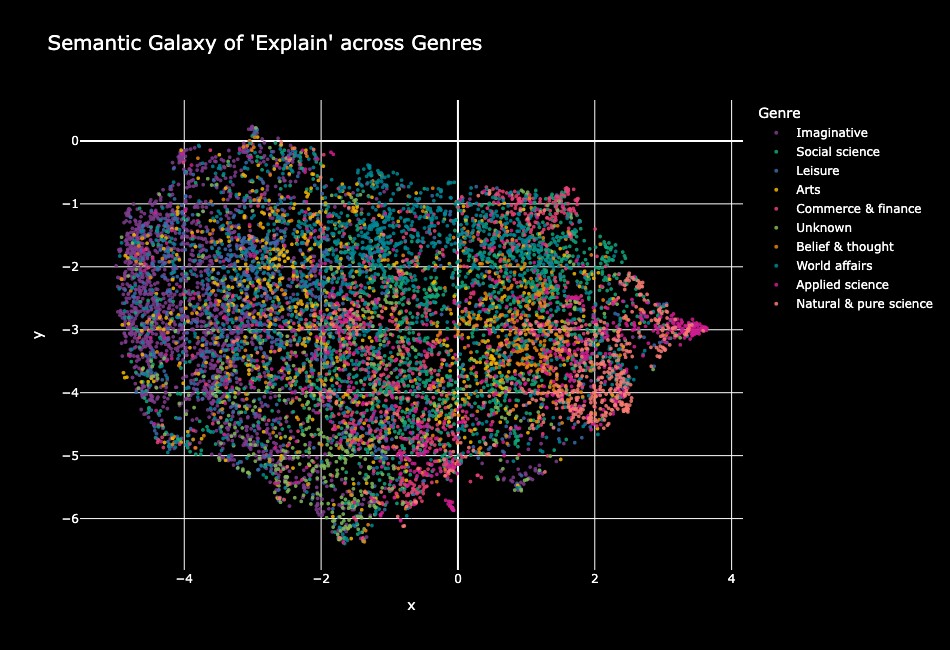
explain の用例 10,000 件を文埋め込み + UMAP で 2 次元に投影し、点の色を BNC のジャンル(Imaginative、Social science、Leisure、Arts、Commerce & finance、Belief & thought、World affairs、Applied science、Natural & pure science 等)で塗り分けたものが Figure 1 です。一見ひとつの「雲」のように見えますが、よく観察すると均質な分布ではなく、複数の意味的に整合的な「星雲(nebulae)」からなる銀河構造が浮かび上がります。左側(x が小さい領域)には Imaginative や Arts といった物語的ジャンルが広く分布し、報告話法・人物描写・視点描写など物語的説明に典型的な特徴が現れます。一方、右側(x が大きい領域)には Natural & pure science や Applied science といった科学的ジャンルが密なクラスターを形成し、因果関係・メカニズム記述・モデルベース推論が集中します。中央付近に広く散らばる World affairs / Commerce & finance / Social science は、その両極を橋渡しする「semantic bridge」として機能していると論文は論じます。
Figure 2:ジャンル重心を重ねた意味銀河
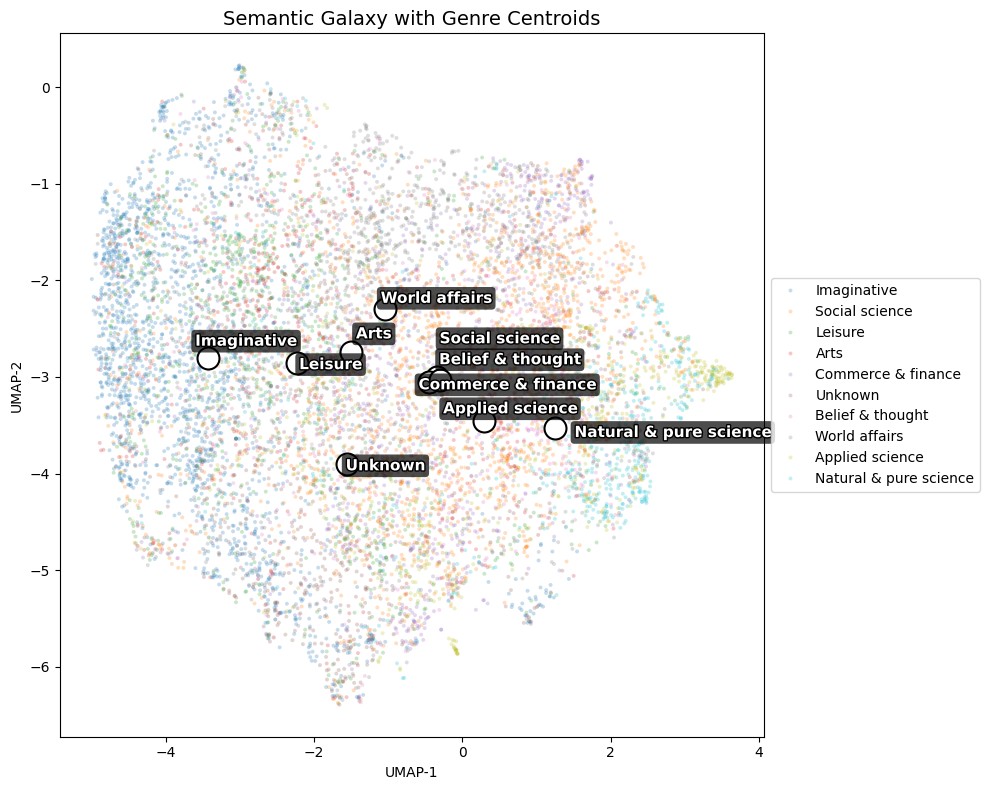
Figure 2 は、各ジャンルの重心(centroid)を UMAP 平面上に重ねた図です。ジャンルごとに「平均的な意味位置」が異なる──Imaginative は左、Natural & pure science は右下、World affairs は中央上、Social science / Belief & thought / Commerce & finance / Applied science は中央に密集──ことが明示されます。重心同士の重なり具合は、ジャンル間で共有される言語資源の量を反映しています。たとえば Social science と World affairs の重心が近接しているのは、両ジャンルとも「政策が地域に与える影響を explain する」のような因果帰属とメタ言説的フレーミングを共通の手段として用いているためです。Figure 1 と 2 が示すのは、「説明」は単一の機能ではなく、複数の言説伝統が共有する意味銀河の中で、それぞれ特徴的な領域を占める多中心的なエコロジーだ、ということです。
Figure 3:PCA による大域的な意味軸
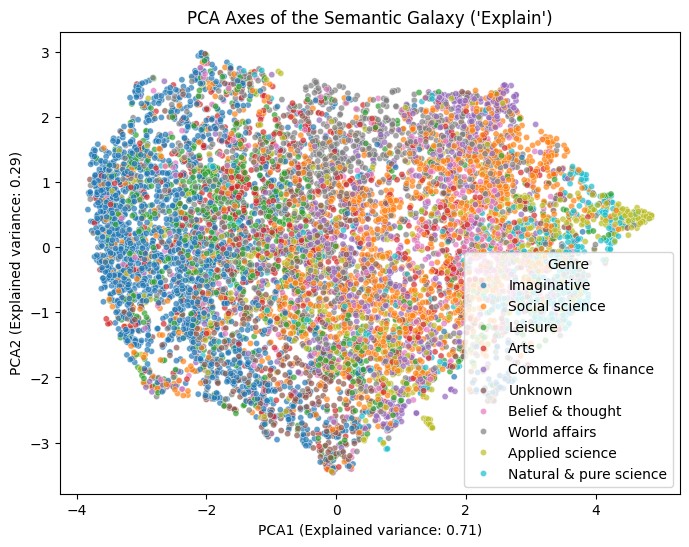
UMAP は局所的な近傍関係を保つ非線形射影なので、データ全体を貫く「大域的な軸」を見るには別の手法が要ります。そこで論文では同じ埋め込み空間に PCA(主成分分析)をかけ、最大分散方向を抽出しました。Figure 3 がその第 1・第 2 主成分平面です。PCA1(横軸、説明分散 71%)は「科学的・因果的説明 ↔ 物語的・対人的説明」の連続体を表し、PCA2(縦軸、説明分散 29%)は「制度的・公的説明 ↔ 個人的・対話的説明」の連続体を表します。GPT-5 で各象限の代表文を解釈させた結果、(右上)「科学的かつ制度的」("changes in pH are caused predominantly by the albumin concentration, which explains the lower slope...")、(左上)「物語的だが制度的」("...ambulance service spokesman Brian Chambers explains the situation")、(左下)「物語的・個人的」("She had explained to him about her mother...")、(右下)「科学的だが対人的」("Explain the advantages and drawbacks of organizing a file...")が見出されました。意味空間は離散的なカテゴリではなく連続的なグラデーションとして組織されているのです。
Figure 4:PCA 象限 × CTM トピックのヒートマップ
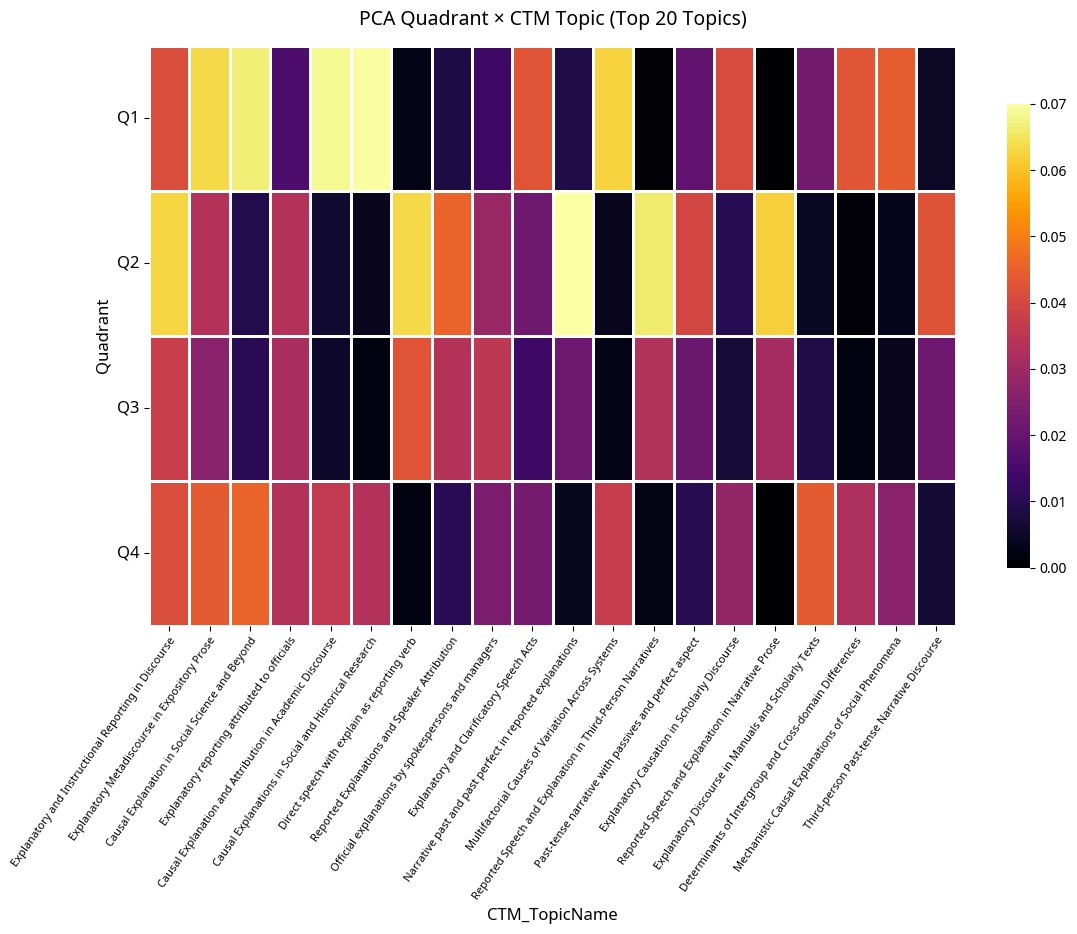
次に、Combined Topic Model(CTM)で抽出した 50 トピックのうち上位 20 トピックを、Figure 3 の 4 つの象限(Q1〜Q4)にどう分布するかをヒートマップで示したのが Figure 4 です。各セルの色が明るいほど、そのトピックがその象限に多く現れることを意味します。PCA1 正方向(右側、Q1・Q4)には Mechanistic Causal Explanations of Social Phenomena のような科学的・メカニズム的トピックが集中し、PCA1 負方向(左側、Q2・Q3)には Past-tense Narrative with Passives and Perfect Aspect のような物語的・報告話法的トピックが集まります。一方、PCA2 正方向(上、Q1・Q2)には Official Explanations by Spokespersons and Managers のような制度的・公的トピックが、PCA2 負方向(下、Q3・Q4)には Explanatory and Clarificatory Speech Acts のような対話的・指示的トピックが分布します。「右上=科学・左下=物語・上=制度・下=対話」という驚くほど整然とした構造が、意味空間の中に潜んでいたわけです。
Figure 5:6 つの説明 constellation(星座)で塗り分けた銀河
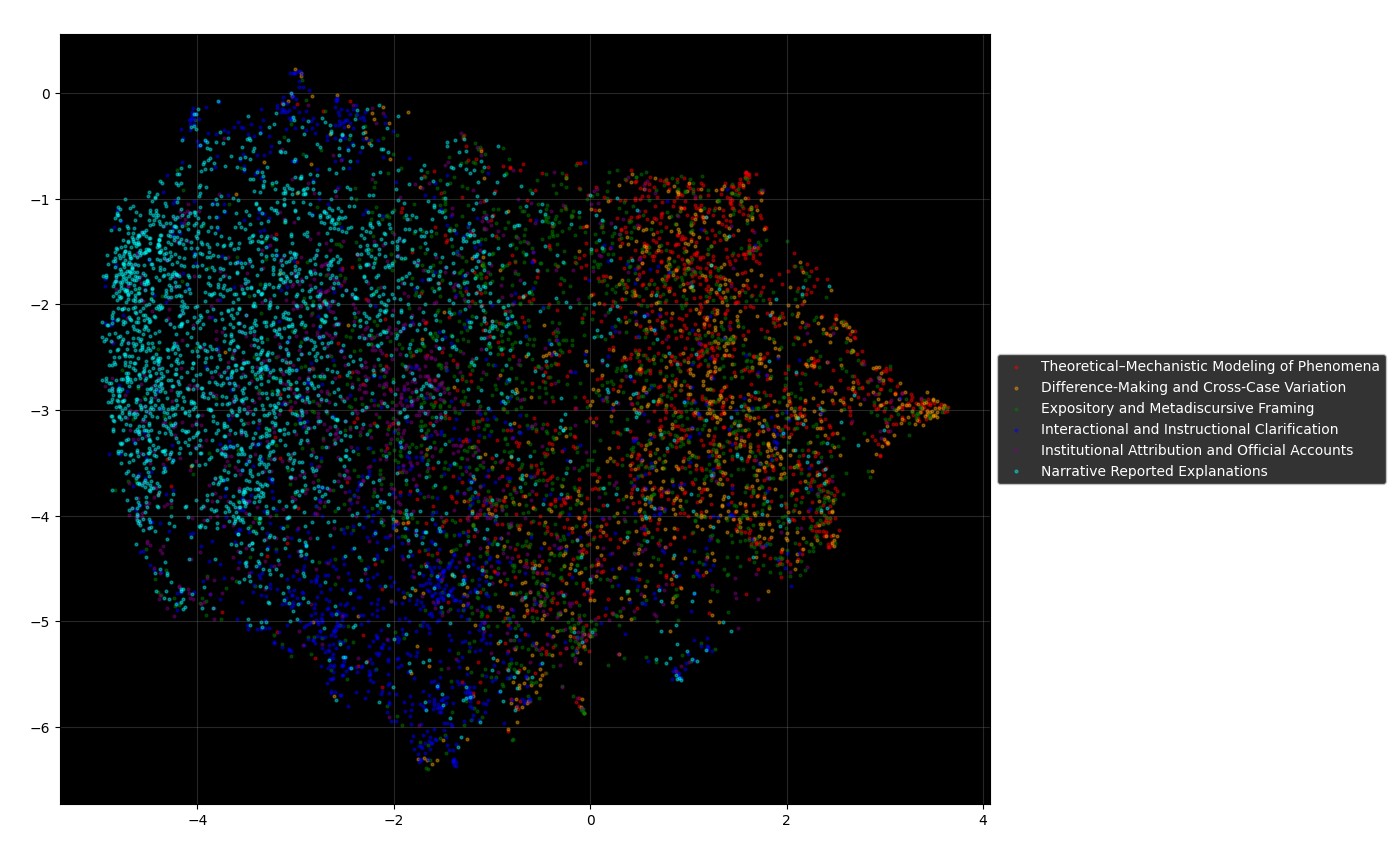
さらに GPT-5 は、トピック間の意味的近接性に基づいて、50 個の CTM トピックを 6 つの上位「説明 constellation(星座)」に組織化しました。Figure 5 はその 6 つの constellation でジャンル色分けを置き換えた銀河図です。点の色は次の 6 種類に対応します:
- ・Theoretical–Mechanistic Modeling of Phenomena(理論的・メカニズム的説明)
- ・Difference-Making and Cross-Case Variation(差異形成的・横断的説明)
- ・Expository and Metadiscursive Framing(解説的・メタ言説的説明)
- ・Interactional and Instructional Clarification(対話的・指示的説明)
- ・Institutional Attribution and Official Accounts(制度的帰責としての説明)
- ・Narrative Reported Explanations(物語的・報告的説明)
各 constellation はUMAP 平面上で内部的に整合的な領域を占めており、銀河の中の「星座」のように見える局所的なクラスターを形成しています。境界はシャープでありながら連続的で、説明実践がランダムに散らばっているのでも完全に分離しているのでもなく、共有された語彙・文法・談話特徴に支えられた「ご近所」のようなパターンをなしている──というのが論文の主張です。
Figure 6:constellation 内のトピック重心を線で結んだ「星座図」
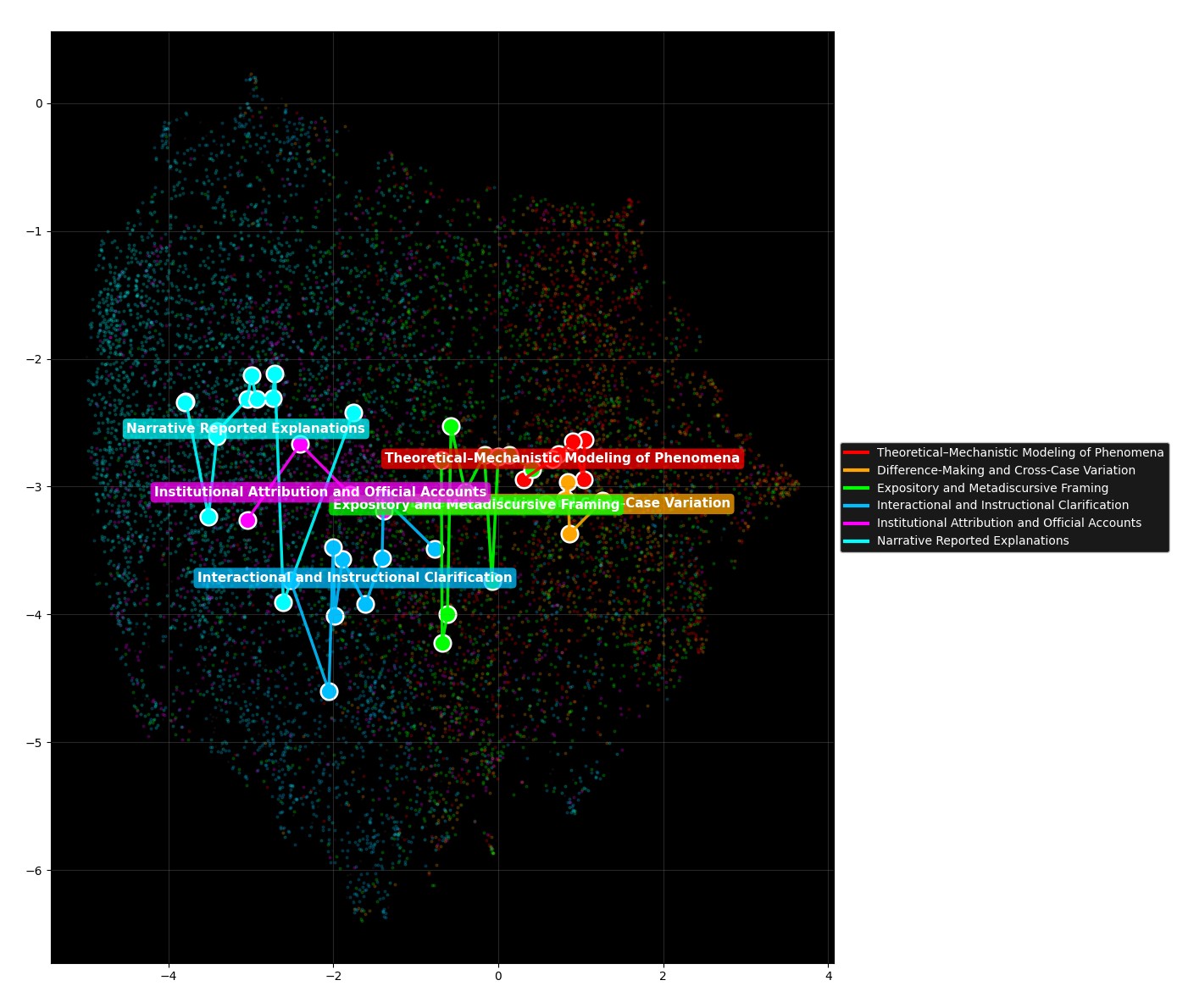
Figure 6 は、各 constellation に属する CTM トピックの重心を線で結ぶことで、銀河の中の「星座図」を描き出した図です。Theoretical–Mechanistic Modeling of Phenomena(赤)は右上に、Difference-Making and Cross-Case Variation(オレンジ)は中央やや右に、Expository and Metadiscursive Framing(黄緑)は中央に、Interactional and Instructional Clarification(水色)は下方に、Institutional Attribution and Official Accounts(マゼンタ)は中央上に、Narrative Reported Explanations(青)は左に、それぞれ「星座」のような位相をもって配置されます。Figure 5 で見えた「説明の 6 つの様式」が、互いに関係づけられた星座群として一望できるわけです。
主な発見:分離ではなく「浸透性のある連続体」
6 つの図を通して浮かび上がるのは、explain が単一の本質を持つ語ではなく、6 つの説明モードからなる多中心的な意味エコロジーを形成しているということです。重要な発見は、6 つの constellation が鋭く分離した離散カテゴリではなく、滑らかに移行しあう「浸透性のある(permeable)連続体」を形成している点です。論文では次のような「連鎖」が指摘されています:
- ・科学的説明 は自然に メタ言説的解説 へとつながる(理論モデル → 教科書的説明)
- ・メタ言説的解説 は 制度的帰責 へと移行する(学術的解説 → 公式説明)
- ・制度的帰責 は 物語的報告 へと滑り込む(公式発言 → 報道叙述)
この連続性こそが、explain が単なる多義語(polysemy)ではなく、社会的実践に根ざした分布的・多中心的な構造であることの証拠です。図 4 のヒートマップで象限間にゼロでない「中間値」のセルが多数あること、図 6 の星座が密接に配置されていることが、この「橋渡し」を視覚的に裏付けます。
constellation 別のスタイル特徴
GPT-5 が各 constellation の代表文を分析して生成したスタイル要約(constellation_styles_gpt5.csv)からは、各 constellation が特徴的な語彙・文法・談話パターンをもつことが分かります:
- ・Theoretical–Mechanistic:因果・モデルベースの語彙で自然・社会現象の根底にあるメカニズムを記述("This theory explains the correlation between the two variables")。
- ・Difference-Making:横断的な比較、説明の十分性、相互作用要因を強調する社会科学的論証。
- ・Expository / Metadiscursive:define / explain / justify といった談話組織化動詞を用いて読者を概念的領域に案内する学術・政策的散文。
- ・Interactional / Instructional:命令形・明確化要求を多用し、対人的に理解を調整する("Please explain what you mean by that")。
- ・Institutional Attribution:explain を報告動詞(reporting verb)として用い、公的説明責任を演じる("The minister explained the government's new strategy")。
- ・Narrative Reported:過去形・受動・完了相を用いて、物語世界内に登場人物の動機・意図・因果推論を埋め込む("He explained that he had been waiting for hours")。
含意:「説明」の脱本質主義的再概念化
これらの結果は、説明(explanation)を単一の論理形式・固定された辞書定義に還元しようとする伝統的な哲学的アプローチへの再考を促します。explain の自然言語使用は、科学的推論・制度的正当化・対人的調整・物語的意味づけ──いずれも「説明」と呼ばれる行為──を含む多中心的な現象であり、その意味は談話文脈に応じて連続的にシフトするのです。
この知見は、Machery (2016) の「実験的科学哲学」、Overton (2013) のコーパスベース科学的説明研究、そして Moretti (2013) の distant reading を統合的に拡張するものとして、説明研究・コーパス言語学・デジタル人文学・科学技術論(STS)に方法論的な貢献をもたらすと論文は主張します。今後の展開としては、justify / clarify / describe など他の説明関連動詞への適用、通時的分析、言語横断的比較、constellation 境界の動的遷移の解析などが提案されています。
Behavioral Profile 分析との対比
同じ BNC を使い、似たような「動詞の語義をボトムアップに抽出する」目的を共有しながら、BP 分析と DCA は方法論的に対照的です:
- ・BP 分析(understand):研究者が理論的に 27 個の素性カテゴリを設計し、用例にラベルを付与してから多変量解析にかける。記号的・離散的で、各クラスターの解釈に直接結びつく明確な特徴が得られる。
- ・DCA(explain):用例をそのまま文埋め込みベクトルに変換し、連続的な高次元意味空間で UMAP・PCA・トピックモデルにかける。分布的・連続的で、研究者があらかじめ素性を設計しなくてもパターンが浮かび上がる。
両者は対立するものではなく、補完的です。BP 分析は仮説検証と語義の理論化に強く、DCA は仮説のない探索と大規模データの可視化に強い。研究目的と問いの性質によって使い分けるのが理想です。
論文ではこの手法を、Moretti (2013) の distant reading(遠読)を拡張した cosmic reading(宇宙的読解)として位置付けています。テキストを「離れて」読むだけでなく、テキストが埋め込まれた高次元意味空間そのものを「銀河」として観察し、そこに浮かぶ「星座」を読み解く──Figure 1〜6 のような可視化は、デジタル人文学が単なるデータ集計から、データの幾何学的構造を解釈する新しい読解実践へと進化していることを象徴しています。
📦 データと再現性:本研究で用いたコードと中間データ(PCA・CTM・GPT-5 ラベル等)はすべて Open Science Framework(OSF)上で公開されており、誰でも追試可能です:
https://osf.io/e95h3/overview?view_only=2bc76853cfb641aeb46161382a4d70e7
自分でコーパス/データセットを構築する:もうひとつの選択肢
ここまでの 6.1〜6.11 はすべて、BNC・BCCWJ・COCA など既存の大規模コーパスを「使う」ことを前提に話を進めてきました。しかし人文学の研究では、既存コーパスではどうしても答えられない問いがしばしば出てきます。そんなとき、研究者には自分でコーパス/データセットを構築するという、もうひとつの本格的な選択肢があります。本節ではそのプロセス(なぜ作るか/何を集めるか/どう整備するか/どう分析・共有するか)を概観します。
なぜ自分で作るのか
既存コーパスは確かに便利ですが、設計時の代表性・収録時期・ジャンル構成によって範囲が決まっています。次のような研究では、既存コーパスではカバーしきれません:
- ・特定の作家・思想家の全集(夏目漱石・西田幾多郎・特定の論文著者など、語法の個人プロファイル分析)
- ・特定のジャンル・専門領域(判例集、特定の SNS コミュニティ、フィクション・ファンフィクション、料理レシピ等)
- ・特定の時代・地域(戦間期の雑誌記事、震災後 5 年間のブログ、ある方言地域のインタビュー等)
- ・既存コーパスより新しい時期(BNC は 1990 年代、BCCWJ は 2001〜2008 年が中心 → 最新の用法を見るには新規構築が必要)
- ・マルチモーダル・新しい形式のデータ(音声 + 文字起こし、画像 + キャプション、動画字幕、対話ログ、ツイートなど)
- ・卒論・修論・個人研究での小規模パイロット(数千〜数万件程度の限定的だが集中的に観察したい資料)
「既存のコーパスに合わせて問いを変える」のではなく、「問いに合わせてデータを集める」──これが自分で構築するという行為の意味です。
何をどこから集めるか(データソースの例)
- ・著作権切れテキスト:Project Gutenberg(英語他)、青空文庫(日本語)、Wikisource、HathiTrust の public domain 部分。古典文学・思想テキストの大規模分析に。
- ・公的・行政データ:国会会議録、判例データベース、官報、政府白書、地方議会議事録。多くはオープンデータとして再利用可。
- ・Web スクレイピング:ニュースサイト、ブログ、フォーラム、レビューサイト。
requests+BeautifulSoupやScrapy、Playwright(動的サイト用)など Python ツールが基本。robots.txt と利用規約の尊重が必須。 - ・SNS API:X(旧 Twitter)、Reddit、Mastodon、Bluesky、YouTube コメント等。ただし規約と料金が頻繁に変わるので最新情報の確認が必要。
- ・音声・映像 → 文字起こし:自分で録音したインタビュー、講義録音、ポッドキャストを Whisper(OpenAI)や whisper-large-v3 / faster-whisper 等で文字起こし。話し言葉コーパスを自前で作れる時代になりました。
- ・OCR:紙資料・歴史新聞・古文書:Tesseract、Google Document AI、Mathpix、最近では GPT-4o / Claude の vision モデルを使ったレイアウト保持 OCR が高精度。くずし字なら NDL 古典籍 OCR モデルなど。
- ・アーカイブ機関のデータ:国立国会図書館デジタルコレクション、Internet Archive、Common Crawl、欧州 CLARIN 系のリソース。
- ・フィールド調査による新規収集:インタビュー、参与観察、アンケート自由記述。新規データなので倫理審査・同意取得が必要。
構築の標準フロー(7 ステップ)
- 研究目的の明確化:何を観察したいのか/何と比較したいのか/規模はどの程度必要か。サンプル数の見積もりはここで決まる。
- 代表性・抽出枠の設計:対象集団(population)に対してどうサンプリングするか。層化抽出か全件か、ジャンル比率をどう揃えるか。少なくとも誰が見ても再現できる手順として記述する。
- データ収集:上述のソースから素データを取得。収集スクリプトをバージョン管理(Git)するのが鉄則。「いつ・どのスクリプトで・どのソースから取得したか」を記録。
- クリーニング:HTML / マークアップ除去、文字コード正規化(NFC 統一)、重複削除、文字化け修正、ヘッダー・フッターなどのボイラープレート除去、空文書除外。
- 構造化とメタデータ付与:各文書(or 各文)に ID、ソース、日付、著者、ジャンル、URL、ライセンスなどのメタデータを添付。JSONL / CSV / TEI XML / Parquet などフォーマットを統一。
- 言語処理アノテーション(必要に応じて):形態素解析(MeCab / Sudachi / Janome / spaCy / Stanza)、文境界、品詞、依存構造、固有表現、語義タグ。Universal Dependencies などの国際標準があれば準拠する。
- 品質管理(QA):サンプリング検品、長さ分布・文字種分布の確認、重複率、ノイズ率の測定。アノテーションがある場合は二人以上で一致率(κ)を測る(→ 6.9 で論じた人手 + AI のハイブリッド設計)。
AI を活用した構築支援
最新の LLM はコーパス構築の各段階でも強力な助けになります(ただし必ず人間による検証を併用するのが鉄則):
- ・クリーニング:「次の Web ページから記事本文だけを抽出して」「広告・関連リンク・著者プロフィールを除去して」など、ボイラープレート除去を文脈判断で実行
- ・メタデータ生成:本文からタイトル・要約・キーワード・ジャンル・推定執筆時期などを自動付与
- ・構造解析:旧い PDF や OCR 結果から段落・見出し・引用・脚注を構造化
- ・音声処理:Whisper による文字起こし、話者分離(diarization)、間投詞・フィラー("えーと")の正規化
- ・アノテーション:6.9 で論じた multi-model + human validation の枠組みで、語義・感情・スピーチアクト・談話機能などを自動付与
- ・外国語対応:機械翻訳との組み合わせで、対訳コーパス(parallel corpus)の自作も現実的になった
なお、AI で生成・処理した部分は必ずプロセスを記録(プロンプト・モデル名・日時・バージョン)しておき、データセット公開時に開示することが研究倫理上の標準になりつつあります。
法的・倫理的な留意点
自分で構築する場合、既存コーパスを使うときよりはるかに多くの責任が研究者にかかります。最低限おさえておくべき論点:
- ・著作権:日本では「著作権法 30 条の 4」(2018 改正)により、情報解析を目的とした著作物の利用は原則自由に認められています。ただし「分析の必要を超えた形での提示・公開(つまり用例を丸ごと再配布する等)」は別途検討が必要。
- ・利用規約と robots.txt:Web サイトには明示/暗示的な利用規約があり、これを無視したスクレイピングは契約違反になりうる。SNS API は規約変更が激しいので最新情報の確認が必須。
- ・個人情報・プライバシー:実名・連絡先・特定地域などが含まれる場合は匿名化(pseudonymization)が必要。EU 圏のデータには GDPR が、日本国内では個人情報保護法が適用される。
- ・インフォームド・コンセント:インタビュー・参与観察などで新規データを収集する場合、調査対象者から事前に書面で同意を取り、撤回権を確保する。
- ・研究倫理審査(IRB):所属機関の研究倫理委員会に審査を申請する。特に医療・教育・脆弱性のある集団を扱う場合は必須。
- ・バイアスと代表性の透明化:完璧に偏りのないコーパスはありえないので、どんなバイアスが想定されるかをデータシートで明示する(後述の Datasheets for Datasets)。
分析する:自作コーパスでも本章の手法はそのまま使える
自作コーパスでも、6.6 で紹介した Sketch Engine への独自コーパスアップロード機能(Sketch Engine for Universities では数百万語規模まで投入可能)、あるいは AntConc(Anthony 開発のフリーソフト)や CasualConc(Mac 向け)、または Python の nltk / spaCy / stanza を直接使った分析が可能です。KWIC・頻度・共起・コロケーション・キーワード抽出など基本機能はすべて利用できますし、6.7〜6.11 で論じた Behavioral Profile 分析・Distributional Concept Analysis も自作コーパスで実施できます。「データさえ自分で揃えば、最先端の手法をすべて自分の研究対象に適用できる」──これが現代コーパス研究のもっとも開放的な側面です。
共有・公開する:FAIR 原則とプラットフォーム
構築したコーパスを他の研究者が再利用できる形で公開することは、現代の研究倫理・オープンサイエンスの中心的価値です。指針となるのが FAIR 原則:
- ・Findable(見つけられる):DOI などの永続識別子を付与し、検索可能にする
- ・Accessible(アクセス可能):認証手順や利用申請があっても、それが明示されていて取得手段が継続的
- ・Interoperable(相互運用可能):標準フォーマット(TEI XML、CoNLL-U、JSONL、Parquet 等)を用いる
- ・Reusable(再利用可能):明確なライセンス(CC0 / CC-BY / CC-BY-SA / CC-BY-NC など)と豊富なメタデータを添える
代表的な公開先プラットフォーム:
- ・OSF(Open Science Framework):人文・社会科学で広く使われる。前節 6.11 の Sugawara (2026) や 6.10 の Sugawara & Kambara (2023) も OSF で公開されている。プロジェクト単位で論文・データ・コード・プロンプトをまとめて DOI 付きで公開可能。
- ・Zenodo:CERN がホスト。GitHub と連動してリリースごとに自動で DOI を付ける機能が人気。50GB まで無料。
- ・GitHub:コード公開の定番。小〜中規模データなら直接置けるし、大規模なら Git LFS や外部ストレージへのリンクで対応。
- ・Hugging Face Datasets:機械学習コミュニティが使う事実上の標準。
datasetsライブラリで直接ロードできる。LLM 時代のデータ公開には特に強い。 - ・CLARIN / NINJAL / LDC / ELRA:言語資源専門のリポジトリ。長期保存性が高く、引用しやすい。
- ・Datasheets for Datasets(Gebru et al. 2018/2021):データセットの背景・収集方法・想定用途・バイアス・倫理的考慮をまとめた「データセットの仕様書」。公開時の添付が国際標準になりつつある。
事例イメージ
- ・卒業論文・修士論文レベル:「ある作家の全短編集(青空文庫から取得)約 100 万字」「ある地域の方言インタビュー 30 時間(Whisper 文字起こし、同意済み)」「Reddit の特定 subreddit 過去 5 年分のスレッド」など。数十〜数百時間で構築可能。
- ・博士論文・研究プロジェクトレベル:「医学論文の Method 章コーパス 5 万件」「19 世紀後半の英国新聞 OCR コーパス 1 億語」「日中対訳パラレルコーパス 10 万文対」など。複数年かけて構築。
- ・国際的に有名な研究者構築型コーパス:CHILDES(言語発達の子ども発話コーパス、MacWhinney)、Switchboard(電話会話)、Penn Treebank(構文注釈)など。研究者個人の問いから出発して、世界中の研究の基盤になった例。
- ・本講義の関連事例:前節 6.11 で紹介した explain の DCA 研究、および 6.10 で紹介した Sugawara & Kambara (2023) の BP 分析は、BNC を「使う」だけでなく、その上に独自の注釈データ・埋め込み・PCA・CTM・GPT-5 ラベル等の中間データセットを構築し、いずれも OSF で公開している。これも一種の「派生コーパス/派生データセットの構築と共有」の例。
コーパスを「使う」だけの研究と「作って共有する」研究は、人文学のなかでも質的に異なる行為です。前者が他者の設計した観察装置から覗くことだとすれば、後者は自分自身で観察装置そのものを設計すること──すなわち、何を「データ」とみなすか、どこまでを研究対象として切り取るか、という研究の前提自体を問い直す行為です。完成したコーパスを公開することは、自分の問いを他者と共有するだけでなく、新しい研究を生み出す基盤資源を社会に提供することでもあります。AI 技術によって構築のハードルが下がりつつある今、人文学研究者が「コーパス/データセットを自作する」選択肢は、これまで以上に現実的なものになっています。