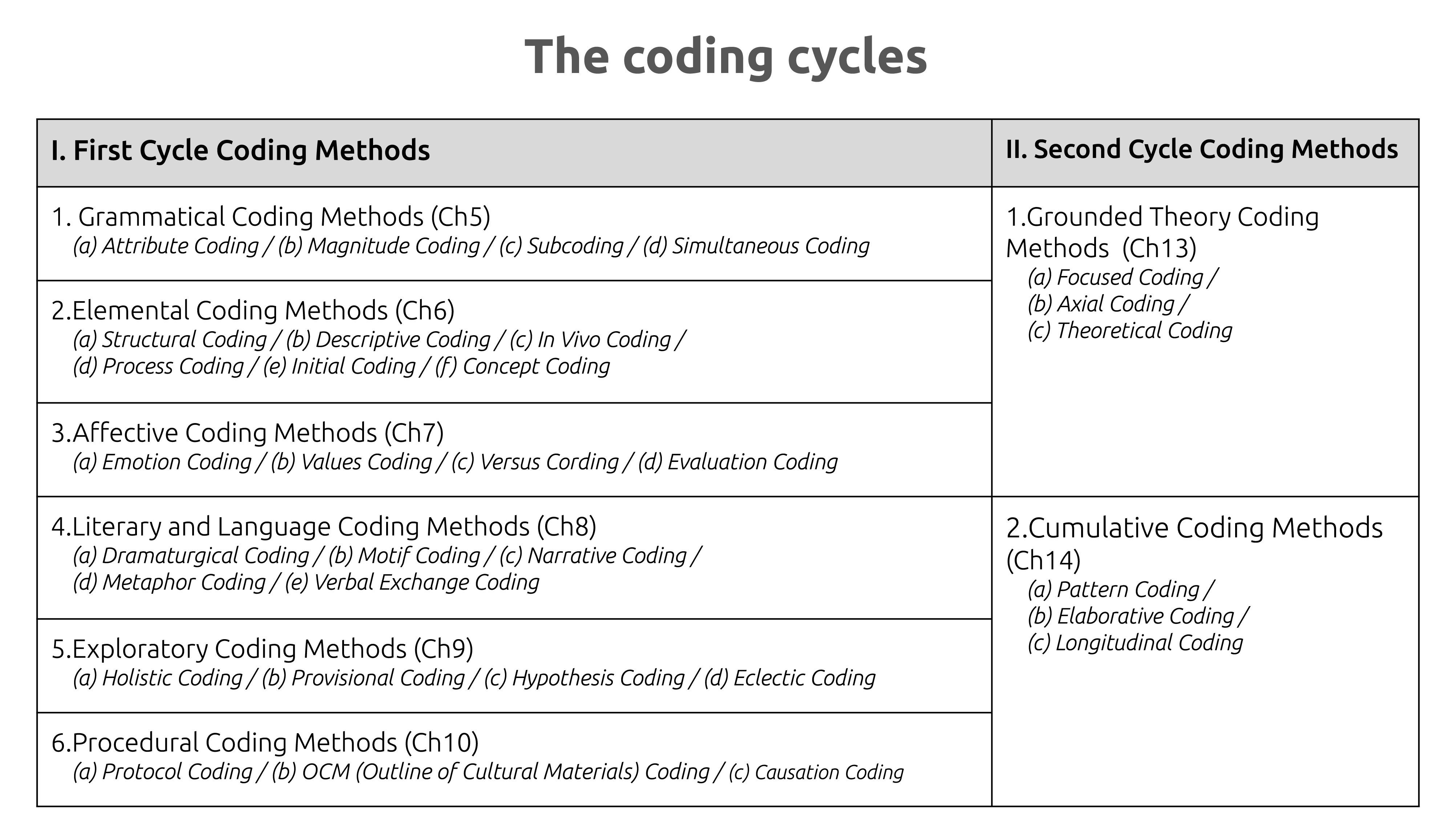
質的データ分析の基礎
人文学的探究としての質的分析を、その理念から手順まで一望する
質的データ分析とは何か
質的データ分析とは、インタビュー記録や観察メモなど 数値化できないデータ に対して意味を読み解く手法です。文章や会話、画像といった非数値データを題材に、その中から共通するテーマやパターンを探し出します。
収集したデータに対し コード化(コーディング) などの方法で意味を解釈し、人々の関係性や価値観・概念について理解を深めていきます。質的分析の成果は統計的な数値ではなく、データに潜む 意味や物語 として表現される点に特徴があります。
🐘例えばインタビューの文字起こし、フィールドノート、日記、写真・映像——どれも数値では捉えられない素材ですが、丁寧に読み解くことで、人間の経験や社会文化的な現象を深く理解することができます。
なぜ質的分析を行うのか
質的分析の目的は、数値では捉えきれない文脈に基づいた深い洞察を得ることにあります。人間の行動や語りには複雑な背景や意味が込められており、質的手法によってそれら「なぜ」「どのように」を解明できます。
人文学では、時間をかけてゆっくりと考察を深める姿勢が重視されます。これは理工系の「高速に結果を求める科学(ファストサイエンス)」に対し、人文系では スローサイエンス とも呼ばれるゆったりとした探究を尊ぶ伝統に対応しています。データにじっくり向き合うプロセスは 発酵 に喩えられるように、時間の経過が思考を成熟させる重要な役割を果たします。
⏳ 時間の流れへの意識
現在目の前の現象だけでなく、そこに至る過去をひもとき未来を想像することで、現象の意味をより深く理解しようとします。
🔄 反復と内省
研究者自身が内省と対話を繰り返しながら解釈を練り上げ、データの断片が次第につながり合い 一貫した物語(ナラティブ) として見えてきます。
📖 物語作成という創造的営み
質的研究における「物語作成」とは、分析によって見出した関係性や概念をもとに、現象をうまく説明できるストーリーを構築する作業を指します。データから結論を引き出すだけでなく、研究者が見出した意味を読者に伝わる形で再構成する創造的な営みです。
コーディングの基礎概念
質的データ分析の核心作業が コーディング(コード化) です。質的データの一部分(テキスト断片など)に対して、その内容を表すラベル(コード)を付ける作業を指します。コードは通常、データ中のテーマや特徴を端的に表現した短い言葉やフレーズです。
例えばインタビューで「大学のサークル活動が無駄に感じる」という発言があった場合、「サークルに対する否定的見方」というコードを付与するイメージです。コードを付けることで、膨大なテキストから重要な要素を抽出し整理できるようになります。
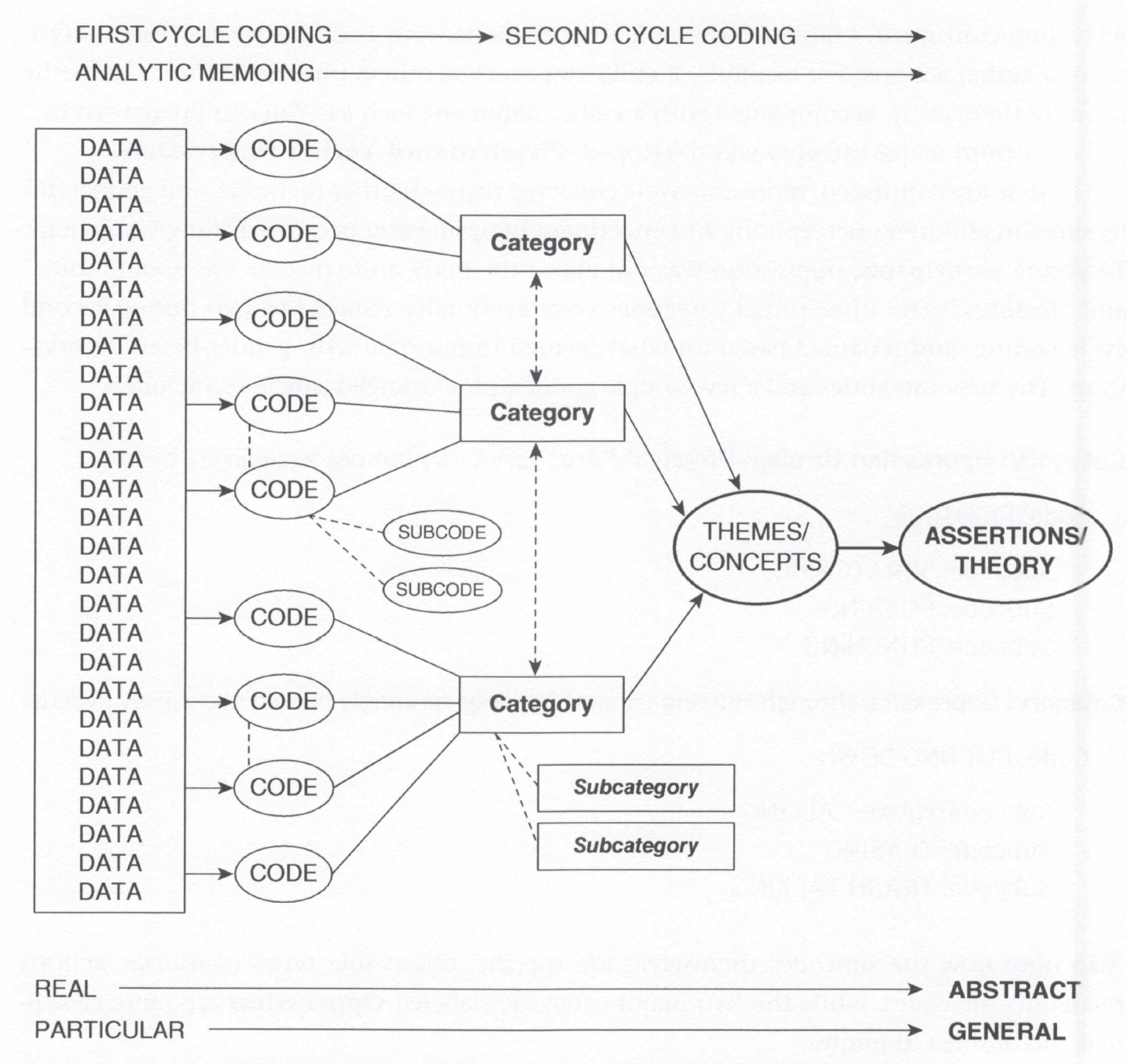
Saldaña 2021, Fig 1.1:データ → コード → カテゴリー → テーマ/概念 → 理論
この図は Johnny Saldaña の提唱するコード化プロセスの簡略モデルです。左側に複数のデータがあり、それぞれに第一次サイクルのコードが付与され、関連するコードがカテゴリー(サブカテゴリー)にまとめられ、さらにいくつかのカテゴリーが テーマ/概念 へと発展し、最終的に研究の 主張や理論 に結びつく——という流れを示しています。具体から抽象へ、特殊から一般へ、というベクトルが分析の基本構造です。詳しくは Part Ⅳ(コラム) で。
8.1.3.1 コードの種類と視点
- ●記述的コード/解釈的コード:表面的な内容をそのまま表す記述的コードと、背後の意味を読み取る解釈的コード。例:「仕事の不満」(記述的)⇄「アイデンティティの危機」(解釈的)。初心者はまず記述的コードから始めるのが無難。
- ●インヴィボ・コード(In Vivo):参加者自身の語りから抽出する。「心が折れた」のような印象的な表現をそのままコード名に。当事者の世界観を尊重できる。
- ●帰納的コード化/演繹的コード化:データから直接コードを生み出す帰納的(ボトムアップ)、既存の理論や枠組みに沿って当てはめる演繹的(トップダウン)。実際の研究では、まず帰納的にオープンコードを生成し、後で理論を参照して洗練するという手順をとることが多い。
- ●多段階のコード化:グラウンデッド・セオリーのオープン → アクシアル → セレクティブのように複数段階で行うこともある。具体から抽象へ、段階的に抽象度を上げて理論的理解につなげる。
- ●コードブックの活用:コードが増えてきたらコードブック(コード一覧表)を作る。コード名・定義・具体例を記録しておくと、時間が経っても一貫した基準で適用でき、共同分析でも認識を揃えられる。
🎉 独りよがりに陥らない
分析者の主観が強く入りすぎるとデータからかけ離れたコード付けをしてしまう恐れがあります。可能であれば自分の付けたコードが妥当か、指導教員や他の研究者と ディスカッション しましょう。複数の人が同じ逐語録にコードを付けてみて結果を比べると、自分では見落としていた視点に気づけます。質的分析には絶対的な「正解」はありませんが、データに根ざした説得力ある解釈を目指しましょう。
質的分析と量的分析
質的分析と量的分析にはアプローチの違いがあります。主要な点を整理します。
| 観点 | 質的分析 | 量的分析 |
|---|---|---|
| データの性質 | テキスト・映像・音声データ(内容や意味に焦点) | アンケート集計や実験の測定値などの数値データ |
| 目的と問い | 「何が起きているか」「なぜ」「どのように」(帰納的) | 「どの程度か」「違いは有意か」(演繹的) |
| 研究デザイン | 柔軟。状況に応じて方法を変更・調整できる | 手順が厳密に定型化される |
| データ量と結果 | 少数のケースを深掘り、文章や概念モデル、事例の物語 | 多数のサンプル、数表・グラフ・統計指標 |
| 一般化範囲 | 特定の状況や文脈に密着。一般化には慎重さが必要 | 広範な対象への一般法則。文脈差異は捉えにくい |
🌉 質的・量的を架橋するデータサイエンス
近年では両者を橋渡しするデータサイエンスの技法も登場しています。トピックモデリングや自然言語処理(NLP)といった計算手法により、大量のテキストデータからパターンや潜在的テーマを自動抽出することが可能です。コンピュータによる定量的処理と研究者による定性的解釈を組み合わせる 混合手法 が、現代の質的研究で広まりつつあります(第12〜14回で扱います)。
質的分析のワークフロー
質的データを分析する基本的な流れは、次の 7 ステップとして整理できます。実際には直線的ではなく反復的に進み、各段階を行きつ戻りつしながら理解を深めていきます。
研究計画とデータ収集:目的・問いを設定し、それに沿ってデータを集める。インタビュー、フィールドワーク、自由記述、日記、文書資料、ネット投稿など、多様な質的データが対象になる。倫理的配慮(同意取得、個人情報保護)も重要。
データの準備(逐語録):音声は逐語録(トランスクリプト)を作成。理想的には24 時間以内に。「えー」「あー」など躊躇や沈黙も意味を持つ場合は記録する。バックアップを忘れずに。
データの精読・全体把握:何度も読み返し、内容や雰囲気をつかむ。先入観をできるだけ排し、生データを丹念に読む。最初はパターンを直感的に感じ取ることを重視。
データの分割とコード化:テキストを意味のある小さな単位(語りの断片)に区切り、それぞれにラベル(コード)を付与する。一つの断片に複数コードを付けても構わない。
コードのグループ化とカテゴリー化:似たコード同士をまとめて上位のカテゴリーを作る。日本では KJ 法 と呼ばれるカード分類の手法でグルーピングすることも。バラバラな発言から抽象的なテーマやパターンが浮かび上がる。
解釈と結論の導出:カテゴリー同士の関係を考え、データが語るストーリーラインや理論モデルを構築する。質的分析で最も創造的で重要な部分。
結果の報告と検証:読者がデータを追体験できるよう具体的な引用を示しながら論じる。信頼性のためトライアンギュレーション(多角的検証)も実施。匿名化など倫理的配慮も最後まで欠かさない。
⌨️ ステップ 2 の足元:タッチタイピング
逐語録作成は質的研究の地味だが基礎的な作業です。タッチタイピング(キーボードを見ずに正確に打つ技術)が身についていると、文字起こしの精度と速度がまるで違ってきます。ホームポジション(下図 F・J キーの突起)を意識し、各指を担当キーに戻す習慣を身につけましょう。文字起こしの自動化(第 7 回 Whisper)と組み合わせれば、誤認識の修正もスムーズです。
ホームポジション(A・S・D・F/J・K・L・;)から指を動かす
「発酵思考」としての質的分析
質的分析のプロセスは、パン作りにおける 発酵 の過程に喩えられます。時間をかけて材料を醸すことで美味しいパンができるように、データにも時間を与えて熟考することで深い解釈が得られます。

発酵思考の 5 段階(菅原 2025)
🌾
① 材料を集める
データ収集(インタビュー・観察)
🥖
② 生地をこねる
整理と一次分析(コード化)
😴
③ 生地を寝かす
熟考とメモ(間をとる)
🫧
④ 発酵させる
解釈・テーマ抽出・物語作成
🔥
⑤ 焼き上げる
執筆・報告
①材料を集める:研究テーマに沿って、インタビュー・参与観察・関連資料を集める。多様な「材料」が、後の分析の土台になる。
②生地をこねる:データを読み込み、テキスト化・整理し、内容を細かなコードに分類する作業を始める。パン生地をこねて材料を均一に混ぜ合わせるように、生のデータを扱いやすい形にほぐす。
③生地を寝かす:一通りコード化したら、少し時間を置いてデータと分析メモを振り返る。間を取ることで新たな発見が生まれる。寝かせてから読み返すと、見過ごしていた重要なパターンに気づくことがある。
④発酵させる:浮かび上がったカテゴリやパターンをまとめ、より大きな テーマや概念 を抽出する。コード→カテゴリ→テーマ→理論へと分析のレベルを段階的に高め、データに内在する物語が形作られていく。
⑤焼き上げる:分析によって見出したテーマや物語を、論文やレポートの形に整える。引用を示しつつ、研究結果を物語として伝達する。
📌 ①〜⑤は一度ずつ行えば完了するものではなく、実際には ①〜④を何度も往復しながら進めます。新たな発見に応じてデータに立ち戻ったり、コードを修正したり——この再帰的プロセスによって、当初は見えなかった深い意味やパターンが少しずつ明らかになっていきます。
プラクシオグラフィー — 実践への焦点移動
人類学者・哲学者の アネマリー・モル(Annemarie Mol)が提唱する プラクシオグラフィー(Praxiography:実践の記述) は、従来のエスノグラフィーが抱えていた「人間中心主義」や「認識論的な限界」を突破するための、STS(科学技術社会論)由来の方法論的ツールです。
伝統的なエスノグラフィー(特に解釈的・象徴的エスノグラフィー)との核心的な違いは、「意味(Meaning)」から「物質的な実践(Practice)」への焦点の徹底的な移動にあります。質的分析で何を見るか、何にコードを付けるか、という最も実践的なレベルにも影響を与える視点です。
📜 8.1.7.1 背景:存在論的転回(Ontological Turn)の系譜
プラクシオグラフィーの基盤には、社会科学が「現実(自然)は一つで、人間の解釈(文化)が複数」という前提を根本から問い直した 存在論的転回(Ontological Turn)という大きなパラダイムシフトがあります。3 ステップで整理しましょう。
① 認識論から存在論へ
かつての社会科学(特に 科学知識の社会学:SSK など)は 認識論(Epistemology)を中心に据えていました。「科学者という人間社会が、いかにして実験結果を解釈し、真理を構築(合意)していくか」を分析する立場です。ここでの主役は人間であり、物質や自然は「解釈される受動的な対象」でした。これに対し、存在論的転回は 存在論(Ontology)、つまり「現実(モノ)そのものが、いかにして立ち上げられるか」へと問いの焦点を移しました。人間の解釈ではなく、物質を巻き込んだ「実践」こそが現実を作っているという視点です。
② 出発点:アクターネットワーク理論(ANT)
この転回の強力な原動力となったのが、1980 年代に ブルーノ・ラトゥール、ミシェル・カロン、ジョン・ロー らが提唱した アクターネットワーク理論(ANT) です。最も革命的な点は 「対称性の原理」(Principle of Symmetry)を打ち立てたこと——人間(科学者・政治家・患者)と非人間(顕微鏡・微生物・ホタテ貝・書類)を全く対等な「アクター」として扱うルールです。科学的な事実や社会の秩序は、人間の意図だけで決まるのではなく、人間と非人間が結びついた「異種混交的なネットワーク」の効果として生み出される、と。物質が能動的なエージェンシー(行為主体性)を獲得した瞬間でした。
③ モルと「ポスト ANT」:多重性と政治
初期 ANT は「ネットワークが安定し、一つの強固な事実(ブラックボックス)が作られるプロセス」に注目しがちでした。しかし 1990 年代後半から、アネマリー・モル や ジョン・ロー ら(ポスト ANT)はネットワークが常に流動的で、ほつれ、複数の現実が共存している状態(多重性) に目を向けます。モルの『The Body Multiple(多重身体)』は決定的でした——彼女は、ネットワークが 異なる実践(診察・X 線撮影・手術)に分岐し、それぞれが異なる現実(存在)を立ち上げている ことを示しました。
構築主義 vs 存在論的転回(比較表)
| 比較軸 | 構築主義(認識論的) | 存在論的転回(存在論的) |
|---|---|---|
| 主な問い | 社会はいかに「真理」を解釈・合意するか? | 実践はいかに「現実」そのものを立ち上げるか? |
| 非人間の扱い | 人間に意味づけられる「受動的な対象」 | 人間と共にネットワークを構成する「能動的なアクター」 |
| 現実の捉え方 | 自然(対象)は一つ、文化(見方)は複数 | 実践の数だけ現実がある(多重現実) |
| 究極の関心 | 知識の相対性を暴くこと | どの現実を立ち上げるべきかという「存在論的政治」 |
🔑 Key insight:存在論的転回が行き着く先は、単なる哲学的な思弁ではありません。「もし現実が実践によって立ち上げられる(可変的な)ものならば、私たちは より良い現実を立ち上げるための実践(デザインやツール)をいかに選択すべきか」という、極めて実践的・倫理的な問い(存在論的政治)への到達です。カレン・バラッドの アジェンシャル・リアリズム(エージェンシー的実在論)、フェミニスト科学哲学、新唯物論(ニュー・マテリアリズム)もこの大きな潮流に合流しており、現代思想を牽引する最もダイナミックな領域の一つです。
🔀 8.1.7.2 プラクシオグラフィーの 3 つの転換
①
問いの焦点
「どう意味づけているか」→「どう立ち上げているか」
従来:人々の「意味づけ」「信念」「世界観」を探求する 認識論。プラクシオ:実際に何が行われているか(Doing)、対象が誰の・どのような実践を通じて 立ち上げられている(Enact されている) かを観察する 存在論。「彼らが何を信じているかは重要ではない。彼らが何をしているかを見よ」(Mol)。
②
アクターの範囲
人間中心 → 異種混交ネットワーク
従来:記述の主役は圧倒的に「人間」。語り・ルール・人間同士の権力関係が中心。プラクシオ:人間だけでなく 非人間(ツール・機械・ソフトウェア・書類・空間レイアウト) も同等のアクターとして記述する(ANT の系譜)。医師の診断を記述する際、医師の「思考」だけでなく、メス・顕微鏡・カルテの入力フォーマットといった物質的要素が、いかに協働して「病気」を形作っているかをフラットに追跡する。
③
現実の捉え方
単一現実の複数視点 → 多重現実の調整
従来:「現実は一つ」で、それに対する人間の視点や文化的解釈が複数ある(多元的)という前提。プラクシオ:実践が違えば、立ち上がる 現実そのもの が異なる(多重現実)。「異なる見方をどう統合するか」ではなく、「異なる現実が、現場でどう衝突し、あるいはパッチワークのように 調整(Coordinate) されているか」を記述のゴールに据える。
🎯 8.1.7.3 QDA におけるコーディングの実践的違い
これらの違いは、フィールドノートやインタビュー記録を分析・コーディングする際の 具体的な作業プロセス にも直結します。
| 比較軸 | 従来のエスノグラフィー的コーディング | プラクシオグラフィー的コーディング |
|---|---|---|
| 注目する品詞 | 名詞・形容詞(感情・価値観・概念) | 動詞(切る・測る・入力する・調整する) |
| 抽出する対象 | 語り手の「解釈」や「信念」 | 物質・ツール・身体が絡む「動作・操作」 |
| 分析のゴール | 共通のテーマや文化的な世界観の抽出 | 対象が立ち上げられ、調整されるプロセスの追跡 |
📌 QDA ソフトでのノード設定:質的分析ソフトを使ってテキストコーディングを行う際、プラクシオグラフィーでは 「被験者がどう感じたか」という心理的・意味的なノードよりも、「どのツールを使い、どう動いたか」という物質的・実践的なノード を細かく設定していくことになります。対象の解釈を巡る議論から抜け出し、テキストやデータ、そしてインターフェースといった 非人間アクターと人間の「相互作用(実践)」そのもの を記述する上で、プラクシオグラフィーは 非常に解像度の高いレンズ を提供してくれます。
🛠️ 8.1.7.4 これからの QDA ソフトウェア設計への示唆
プラクシオグラフィーの視点から既存の QDA ソフトを見直すと、「単一の階層構造に押し込める」「矛盾を解消する」といった従来の設計が、多重現実を扱う妨げ になっていることが見えてきます。本授業で使う minimalQDA も含めて、これからの QDA ツール設計には次のような方向性が考えられます。
① 階層型ツリーから「ブランチ(分岐)」と「並行世界」へ
既存の QDA は、大項目の中に小項目を入れ込む 階層構造(ツリー) を強要しがちです。しかし、あるインフォーマントのひとつの語りは、「抑圧の物語」という現実と「ささやかな抵抗の物語」という現実を 同時に立ち上げる ことがあります。
Git 的な解釈のブランチ設計:同一テキストに対して「解釈 A のレイヤー」「解釈 B のレイヤー」を 並行して作成(分岐)。両者をすり合わせて一つの正解を出すのではなく、画面上でパタパタと切り替えたり、半透明で重ね合わせたりすることで、「ここでは二つの現実がせめぎ合っている」という状態 そのもの を分析の対象として扱います。
② 「矛盾」をバグではなく仕様として扱う空間
複数の現実が衝突する場所は、分析において 最も豊かな鉱脈 です。整合性を取りに行くのではなく、矛盾を 記述に値する現象 として残す。
摩擦のヒートマップ:異なる解釈レイヤーや、異なるタグが重なり合って 「渋滞」しているテキスト部分 を、ヒートマップのように熱量を持って可視化します。「ここは複数の現実がスパークしている重要なノードだ」と 直感的に気づける 設計です。
📌 プラクシオグラフィーは 従来のコーディングを置き換えるもの ではなく、「もう一つのレンズ」として併用するのが現実的です。記述的コードや解釈的コード(8.1.3 節)で意味の世界を捉えつつ、動詞ベースのプロセス・コードや、人間と非人間の絡まりを示すコードを 並走 させる——そうすると、同じデータから 2 通り(あるいはそれ以上)の現実が立ち上がってきます。これが minimalQDA で「複数のカテゴリ色を同じテキストに重ねる」操作の理論的背景でもあります。
コーディング作業を支援するツール
質的データのコーディングは、紙とペンを使ったアナログな方法から専用ソフトウェアまで様々な手法で行えます。
✏️ アナログ(付箋・KJ法)
プリントした逐語録にマーカーでハイライト、付箋で発言断片を書き出して机上でグルーピング。データに直接触れながら考えられる利点があるが、データ量が増えると管理が難しい。
💻 身近なデジタルツール
Google ドキュメント・Word のコメント機能、Excel・スプレッドシートでの表形式管理など。複数人での同時編集も可能。特別なソフトがなくても基本作業は実施できる。
🏢 CAQDAS(専用ソフト)
NVivo、MAXQDA、ATLAS.ti などのコンピュータ支援質的データ分析ソフト。大量データの取り回し・コードでの検索・可視化に強い。ただし有料で学生には高額。
🗺️ マインドマップ
コードからカテゴリーへの体系化を支援。カテゴリー間の関係や階層構造を 2 次元空間にマッピングすることで、リスト表示では見えにくい概念間のつながりを直感的に把握できる。
🎁 本授業では:minimalQDA を使います
商用 CAQDAS は強力ですが、ライセンス費用とインストールが学生にはハードル。本授業では、これらのエッセンスを取り出してブラウザだけで動く軽量ツール minimalQDA を用います。次の Part Ⅱ で紹介します。